Abstract
OpenMP 是 Open Multi-Processing 的简称,是一个应用程序编程接口 (API),由一群计算机硬件和软件的主要供应商联合定义。 OpenMP 为共享内存并行应用程序的开发人员提供了一个可移植、可扩展的模型。是一个可用于显式指导多线程、共享内存并行性的应用程序编程接口。
主要由以下三个 API 组件组成:
- 编译器指令 Compiler Directives
- 运行时库例程 Runtime Library Routines
- 环境变量 Environment Variables
OpenMP 并不能保证以下几点:
- OpenMP 是一个标准,但每个编译器厂商可以根据自己的实现方式来支持这个标准。不同的实现可能会导致同一段代码在不同编译器上表现不一致。
- OpenMP 并不能保证代码在所有情况下都能最有效地利用共享内存。如何高效地使用共享内存取决于具体实现和硬件架构。程序员需要根据具体情况进行优化。
- OpenMP 不会自动检查代码中的数据依赖性(data dependencies)、数据冲突(data conflicts)、竞争条件(race conditions)或死锁(deadlocks)。这些问题需要由程序员手动检查和解决。
- OpenMP 并不负责检查代码是否会导致程序被归类为不合规(non-conforming)。程序员需要确保代码符合 OpenMP 标准和规范。
- 当在并行执行中进行文件输入输出操作时,OpenMP 不保证这些操作是同步的。这意味着多个线程同时读写同一个文件时,可能会导致竞态条件(race conditions)或数据损坏。
OpenMP 的目标在于:
- 标准化:提供各种共享内存架构/平台之间的标准。
- 使用方便:提供实现粗粒度和细粒度并行的能力。
- 可移植性:适用于多语言多平台
- 精简高效 Lean and Mean:使用一组简单且有效的指令。
OpenMP Programming Model
共享内存模型
OpenMP 专为多处理器/核心、共享内存机器而设计。底层架构可以是共享内存UMA或NUMA。
OpenMP 执行模型
基于线程的并行性:通常,线程的数量与机器处理器/核心的数量相匹配。
显式并行性:OpenMP 为程序员提供了对并行化的完全控制,并行化可以像获取串行程序并插入编译器指令一样简单。
Fork-Join 模型:所有 OpenMP 程序都以单个进程开始:主线程。主线程按顺序执行,直到遇到第一个并行区域构造。
- FORK:主线程然后创建一组并行线程。
- JOIN:当团队线程完成并行区域构造中的语句时,它们同步并终止,只留下主线程。
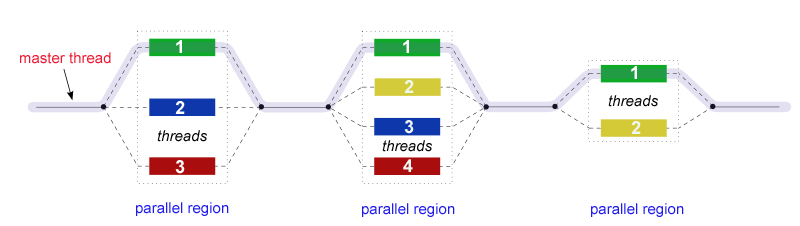
基于编译器指令:通过使用嵌入在源代码中的编译器指令来实现。
嵌套并行性:API 允许将并行区域放置在其他并行区域内。
动态线程: API 允许运行时环境动态更改用于执行并行区域的线程数量,旨在促进更有效地利用资源。
输入输出:OpenMP 没有并行 I/O 的内容,确保 I/O 在多线程程序上下文中正确执行完全取决于程序员。
OpenMP API Overview
编译器指令
OpenMP 编译器指令可用来生成并行区域、在线程之间划分代码块、在线程之间分配循环迭代、序列化代码块和实现线程之间的同步。
格式:sentinel directive-name [clause, ...] |
运行时库例程
这些库例程可以用来设置和查询线程数、查询线程标识符 ID、设置和查询动态线程等等。
#include <omp.h> |
环境变量
OpenMP 提供了多个环境变量来控制运行时并行代码的执行。如设置线程数、指定循环的划分方式、将线程绑定到处理器等。
export OMP_NUM_THREADS=8 |
编译 OpenMP 程序
在 GNU Linux 中,添加 -fopenmp 标识就可以了。
OpenMP Directives
指令范围
静态范围:以文本形式包含在指令后面的结构化块的开头和结尾之间的代码。
孤儿指令Orphaned Directive:独立于另一个封闭指令出现的 OpenMP 指令。
动态范围:指令的动态范围包括其静态(词法)范围和其孤立指令的范围。
并行区域构造
并行区域是将由多个线程执行的代码块。
#pragma omp parallel ... { |
当一个线程到达 PARALLEL 指令时,它会创建一个线程组并成为该组的主线程。主线程是该团队的成员,并且在该团队内的线程号为 0。从该并行区域的开头开始,代码被复制,并且所有线程都将执行该代码。平行部分的末端有一个隐含的障碍。只有主线程通过该点之后才继续执行。如果任何线程在并行区域内终止,则该组中的所有线程都将终止,并且在该点之前完成的工作是未定义的。
Work-Sharing Constructs
工作共享结构将封闭代码区域的执行划分给遇到该区域的团队成员。
工作共享结构不会启动新线程。
进入工作共享构造时不存在隐含障碍,但是在工作共享构造结束时存在隐含障碍。
Do / For:共享整个团队的循环迭代。代表一种“数据并行性”。
#pragma omp for [clause ...] newline |
Sections:将工作分成单独的、离散的部分。每个部分都由一个线程执行。可用于实现一种“功能并行性”。独立的 SECTION 指令嵌套在 SECTIONS 指令内。每个 SECTION 由团队中的一个线程执行一次。不同的部分可以由不同的线程执行。如果线程足够快并且实现允许的话,一个线程可以执行多个部分。
#pragma omp sections [clause ...] newline |
SINGLE:指定所包含的代码仅由团队中的一个线程执行,在处理非线程安全的代码部分时可能很有用。
#pragma omp single [clause ...] newline |
组合并行工作共享结构
#pragma omp parallel for \ |
Synchronization
Master 指令
指定一个仅由团队的主线程执行的区域。团队中的所有其他线程都会跳过这部分代码。
#pragma omp master newline |
Critical 指令
指定一次只能由一个线程执行的代码区域。如果一个线程当前正在 CRITICAL 区域内执行,而另一个线程到达该 CRITICAL 区域并尝试执行它,则它将阻塞,直到第一个线程退出该 CRITICAL 区域。
#pragma omp critical [ name ] newline |
Barrier 指令
同步组中的所有线程。当到达 BARRIER 指令时,线程将在该点等待,直到所有其他线程都到达该屏障。然后,所有线程恢复并行执行屏障后面的代码。
#pragma omp barrier newline |
Atomic 指令
指定必须以原子方式更新特定的内存位置,而不是让多个线程尝试写入它。仅适用于紧随其后的单个语句。
#pragma omp atomic newline |
Flush 指令
标识一个同步点,在该点上实现必须提供一致的内存视图。此时线程可见的变量被写回内存。
#pragma omp flush (list) newline |
Ordered 指令
指定封闭循环的迭代将以与在串行处理器上执行相同的顺序执行。要求任何时候有序部分中只允许有一个线程。
#pragma omp for ordered [clauses...] |
数据范围属性条款
Private Clause
将其列表中的变量声明为每个线程私有的。本质上是在线程内声明一个相同类型的新对象,都是未初始化的。
private (list) |
Shared Clause
声明其列表中的变量在团队中的所有线程之间共享。共享变量仅存在于一个内存位置,所有线程都可以读取或写入该地址。
shared (list) |
Default Clause
允许用户为任何并行区域的词法范围内的所有变量指定默认范围。
Run-Time Library Routines
| Routine | 目的 |
|---|---|
| void omp_set_num_threads(int num_threads) | 设置将在下一个并行区域中使用的线程数 |
| int omp_get_num_threads(void) | 返回在执行调用它的并行区域的线程数 |
| int omp_get_thread_num(void) | 返回团队内进行此调用的线程的线程号 |
| int omp_get_num_procs(void) | 返回程序可用的处理器数量 |
| void omp_init_lock(omp_lock_t *lock) | 初始化与锁变量关联的锁 |
| void omp_destroy_lock(omp_lock_t *lock) | 将给定的锁变量与任何锁解除关联 |
| void omp_set_lock(omp_lock_t *lock) | 获得锁的所有权 |
| void omp_unset_lock(omp_lock_t *lock) | 释放锁 |
| double omp_get_wtime(void) | 提供便携式挂钟计时例程 |
环境变量
setenv OMP_SCHEDULE "dynamic" 设置处理器上循环迭代的调度方式 |