MPI 介绍 在90年代之前,编写并发程序非常困难,缺乏统一标准。急需一个消息传递模型使得程序通过进程间传递消息完成任务,易于实现并发程序。逐渐演化成为了现在我们了解的消息传递接口 MPI。
MPI 对于消息传递模型的设计:
通讯器(Communicator) : 定义了一组可以互相通信的进程,每个进程有一个秩(rank)。点对点通信(Point-to-Point) : 通过指定秩和消息标签(tag)进行消息发送和接收。集体性通信(Collective) : 用于处理所有进程间的通信,如广播。
MPI 安装 MPI 只是众多实现中所遵循的一个标准。 因此,这里有各种各样的 MPI 实现,如 Open MPI 和 MPICH 等,这里我们使用 MPICH 为例。
# 手动安装 wget https://www.mpich.org/static/downloads/4.2.1/mpich-4.2.1.tar.gz tar -xzf mpich-4.2.1.tar.gz cd mpich-4.2.1 ./configure --disable-fortran --prefix=/installation/directory/path(root 不可用时指定安装位置) make; sudo make install # 自动安装 sudo apt install mpich # 验证安装 mpiexec --version
Hello World #include <mpi.h> #include <stdio.h> int main (int argc, char **argv) { MPI_Init(NULL , NULL ); int world_size; MPI_Comm_size(MPI_COMM_WORLD, &world_size); int world_rank; MPI_Comm_rank(MPI_COMM_WORLD, &world_rank); char processor_name[MPI_MAX_PROCESSOR_NAME]; int name_len; MPI_Get_processor_name(processor_name, &name_len); printf ("Hello world from processor %s, rank %d out of %d processors\n" , processor_name, world_rank, world_size); MPI_Finalize(); return 0 ; }
MPI_Init:初始化 MPI 环境,创建全局变量和内部变量。MPI_Comm_size:返回 Communicator 中的进程数量。MPI_Comm_rank:返回当前进程的 Rank。MPI_Get_processor_name:获取当前进程所在处理器的名字。MPI_Finalize:清理 MPI 环境。
编译运行(创建 4 个进程,乱序运行):
➜ MPI mpicc -o hello hello.c ➜ MPI mpirun -np 4 ./hello Hello world from processor ceyewan, rank 3 out of 4 processors Hello world from processor ceyewan, rank 1 out of 4 processors Hello world from processor ceyewan, rank 2 out of 4 processors Hello world from processor ceyewan, rank 0 out of 4 processors
在多节点运行,这种情况比较复杂,因为高性能计算集群中机器的配置都是一样的,但是在我们本地,就算你有两台电脑,也很难保证 MPI 的版本、操作系统等完全一致,好在我们有 Docker。
首先,编写 Dockerfile,大致就是要设置好 MPI 环境和 SSH 服务,因为 MPI 采用 SSH 协议发布任务到不同的计算节点上。我们可以让每个节点的 SSH Key 都相同且添加到 authorized_keys 中,那么所有节点之间都将互信。
然后我们执行如下命令:
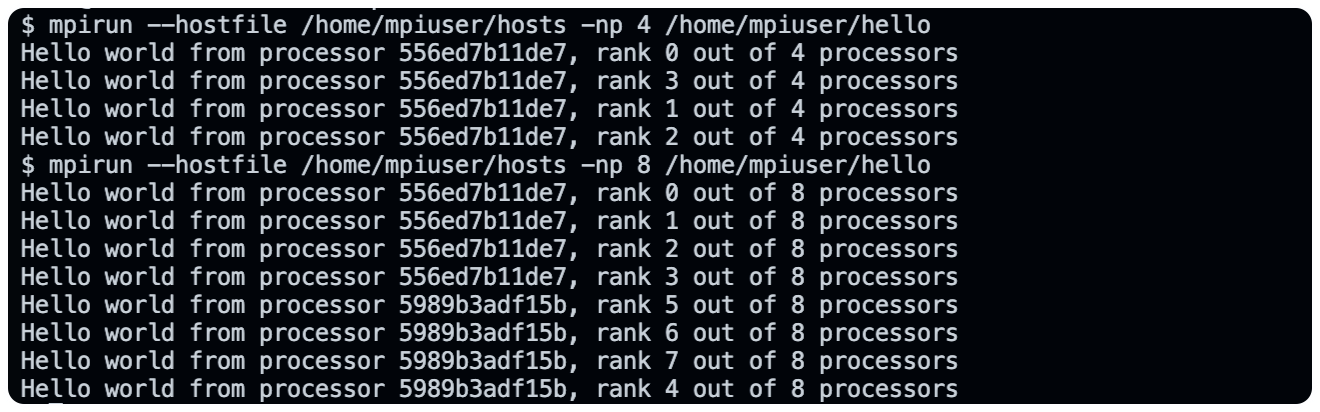
# 利用 Dockerfile 构建镜像 docker build -t mpi_docker_image . # 创建网络 docker network create mpi_network # 创建容器并都连接到同一网络中 docker run -d --name mpi_node1 --network mpi_network mpi_docker_image docker run -d --name mpi_node2 --network mpi_network mpi_docker_image # 查看容器的 IP 地址 docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' mpi_node1 docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' mpi_node2 # 写入 hosts 文件 docker exec -it mpi_node1 /bin/bash echo "172.18.0.2 slots=4" > /home/mpiuser/hosts echo "172.18.0.3 slots=4" >> /home/mpiuser/hosts # 将 hello 文件分发到节点上,如果 node1 作为主节点 docker cp hello mpi_node1:/home/mpiuser/hello docker cp hello mpi_node2:/home/mpiuser/hello # node1 根据 hostfile 执行命令 docker exec -it mpi_node1 /bin/bash mpirun --hostfile /home/mpiuser/hosts -np 8 /home/mpiuser/hello
执行结果如下,本机可以执行,就会优先本机(?也可以是按照 hostfile 顺序);如果本机 slot 不够,就会通过 SSH 分发到其他节点上执行,由于网络延迟的存在,输出结果普遍晚于本地出现。
Send and Receive 发送和接收是 MPI 里面两个基础的概念,这里我们主要讨论阻塞的发送和接收方法,也即同步通信,发送和接收是同步的,确保数据正确传递。
函数接口:
MPI_Send( void * data, int count, MPI_Datatype datatype, int destination, int tag, MPI_Comm communicator) MPI_Recv( void * data, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm communicator, MPI_Status* status)
数据类型有 MPI_BYTE、MPI_INT、MPI_FLOAT、MPI_DOUBLE 等。
pingpong 程序 int main (int argc, char *argv[]) { MPI_Init(&argc, &argv); int world_rank; MPI_Comm_rank(MPI_COMM_WORLD, &world_rank); int world_size; MPI_Comm_size(MPI_COMM_WORLD, &world_size); int partner_rank = (world_rank + 1 ) % 2 ; int count = 0 ; while (count < 10 ) { if (world_rank == count % 2 ) { count++; MPI_Send(&count, 1 , MPI_INT, partner_rank, 0 , MPI_COMM_WORLD); printf ("%d send %d to %d\n" , world_rank, count, partner_rank); } else { MPI_Recv(&count, 1 , MPI_INT, partner_rank, 0 , MPI_COMM_WORLD, MPI_STATUS_IGNORE); printf ("%d recv %d from %d\n" , world_rank, count, partner_rank); } } MPI_Finalize(); return 0 ; }
ring 程序 int main (int argc, char *argv[]) { MPI_Init(&argc, &argv); int world_rank; MPI_Comm_rank(MPI_COMM_WORLD, &world_rank); int world_size; MPI_Comm_size(MPI_COMM_WORLD, &world_size); int partner_rank = (world_rank + 1 ) % 2 ; int token = -1 ; if (world_rank != 0 ) { MPI_Recv(&token, 1 , MPI_INT, world_rank - 1 , 0 , MPI_COMM_WORLD, MPI_STATUS_IGNORE); printf ("%d recv %d from %d\n" , world_rank, token, world_rank - 1 ); token++; MPI_Send(&token, 1 , MPI_INT, (world_rank + 1 ) % world_size, 0 , MPI_COMM_WORLD); printf ("%d send %d to %d\n" , world_rank, token, (world_rank + 1 ) % world_size); } else { token++; MPI_Send(&token, 1 , MPI_INT, world_rank + 1 , 0 , MPI_COMM_WORLD); printf ("%d send %d to %d\n" , world_rank, token, world_rank + 1 ); MPI_Recv(&token, 1 , MPI_INT, (world_rank + world_size - 1 ) % world_size, 0 , MPI_COMM_WORLD, MPI_STATUS_IGNORE); printf ("%d recv %d from %d\n" , world_rank, token, (world_rank + world_size - 1 ) % world_size); } MPI_Finalize(); return 0 ; }
Dynamic Receiving with MPI Probe 上面我们需要提前知道消息长度,接下来,我们开始讨论动态消息。
MPI_Status 结构体包含三个主要信息,分别是发送端秩、消息标签和消息长度。
其中,消息的长度需要使用一个函数才能知道,结构如下:
MPI_Get_count( MPI_Status* status, MPI_Datatype datatype, int * count)
MPI_Recv 可以将 MPI_ANY_SOURCE 用作发送端的秩,将 MPI_ANY_TAG 用作消息的标签。 在这种情况下,MPI_Status 结构体是找出消息的实际发送端和标签的唯一方法。 此外,并不能保证 MPI_Recv 能够接收函数调用参数的全部元素。 相反,它只接收已发送给它的元素数量。 MPI_Get_count 函数用于确定实际的接收量。(类似于 read 函数)
int main (int argc, char *argv[]) { MPI_Init(&argc, &argv); int world_rank; MPI_Comm_rank(MPI_COMM_WORLD, &world_rank); int world_size; MPI_Comm_size(MPI_COMM_WORLD, &world_size); if (world_rank == 0 ) { char *name = "ceyewan" ; int tag = rand() % 100 ; MPI_Send(name, strlen (name), MPI_CHAR, 1 , tag, MPI_COMM_WORLD); printf ("%d send %lu chars to %d with %d tag\n" , world_rank, strlen (name), 1 , tag); } else { int count; char name[100 ]; MPI_Status status; MPI_Recv(&name, 100 , MPI_CHAR, MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, &status); MPI_Get_count(&status, MPI_CHAR, &count); printf ("%d recv %d chars from %d with %d tag\n" , world_rank, count, status.MPI_SOURCE, status.MPI_TAG); } MPI_Finalize(); return 0 ; }
上面我们为了能顺利接收消息,不得不创建了一个很大的数组用于缓存数据。其实也可以使用 MPI_Probe 在实际接收消息之前查询消息大小。
MPI_Probe( int source, int tag, MPI_Comm comm, MPI_Status* status)
可以将 MPI_Probe 视为 MPI_Recv,除了不接收消息外,它们执行相同的功能。 与 MPI_Recv 类似,MPI_Probe 将阻塞具有匹配标签和发送端的消息。 当消息可用时,它将填充 status 结构体。 然后,用户可以使用 MPI_Recv 接收实际的消息。
int main (int argc, char *argv[]) { MPI_Init(&argc, &argv); int world_rank; MPI_Comm_rank(MPI_COMM_WORLD, &world_rank); int world_size; MPI_Comm_size(MPI_COMM_WORLD, &world_size); if (world_rank == 0 ) { char *name = "ceyewan" ; int tag = rand() % 100 ; MPI_Send(name, strlen (name), MPI_CHAR, 1 , tag, MPI_COMM_WORLD); printf ("%d send %lu chars to %d with %d tag\n" , world_rank, strlen (name), 1 , tag); } else { MPI_Status status; MPI_Probe(MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, &status); int count; MPI_Get_count(&status, MPI_CHAR, &count); char name[count]; MPI_Recv(&name, count, MPI_CHAR, status.MPI_SOURCE, status.MPI_TAG, MPI_COMM_WORLD, &status); printf ("%d recv %s(%d chars) from %d with %d tag\n" , world_rank, name, count, status.MPI_SOURCE, status.MPI_TAG); } MPI_Finalize(); return 0 ; }
MPI Bcast and Collective Comm 集体通信指的是一个涉及 communicator 里面所有进程的一个方法。这一节我们介绍 Broadcasting 广播。
集体通信在进程间引入了同步点的概念。这意味着所有的进程在执行代码的时候必须都到达一个同步点才能继续执行后面的代码。在 MPI 中,有一个函数来做同步进程的操作。
MPI_Barrier(MPI_Comm communicator);
广播 (broadcast) 是标准的集体通信技术之一。一个广播发生的时候,一个进程会把同样一份数据传递给一个 communicator 里的所有其他进程。广播的主要用途之一是把用户输入传递给一个分布式程序,或者把一些配置参数传递给所有的进程。
MPI_Bcast( void * data, int count, MPI_Datatype datatype, int root, MPI_Comm communicator)
如果我们使用 MPI_Send 和 MPI_Recv 来实现广播,那么时间复杂度为 O(N)。但实际上是以树的形式广播的,1 到 2 到 4 到 8 的指数增长形式,时间复杂度为 O(logN)。因为节点之间是通过网络连接的,因此,这种优化很有必要。
MPI Scatter,Gather and Allgather MPI_Scatter MPI_Scatter 的操作会设计一个指定的根进程,根进程会将数据发送到 communicator 里面的所有进程。MPI_Bcast 给每个进程发送的是同样的数据,然而 MPI_Scatter 给每个进程发送的是一个数组的一部分数据。
MPI_Scatter( void * send_data, int send_count, MPI_Datatype send_datatype, void * recv_data, int recv_count, MPI_Datatype recv_datatype, int root, MPI_Comm communicator)
第一个参数,send_data,是在根进程上的一个数据数组。第二个和第三个参数,send_count 和 send_datatype 分别描述了发送给每个进程的数据数量和数据类型。如果 send_count 是1,send_datatype 是 MPI_INT的话,进程0会得到数据里的第一个整数,以此类推。如果send_count是2的话,进程0会得到前两个整数,进程1会得到第三个和第四个整数,以此类推。在实践中,一般来说send_count会等于数组的长度除以进程的数量。
函数定义里面接收数据的参数跟发送的参数几乎相同。recv_data 参数是一个缓存,它里面存了recv_count个recv_datatype数据类型的元素。最后两个参数,root 和 communicator 分别指定开始分发数组的根进程以及对应的communicator。
MPI_Gather MPI_Gather 跟 MPI_Scatter 是相反的。MPI_Gather 从好多进程里面收集数据到一个进程上面而不是从一个进程分发数据到多个进程。MPI_Gather从其他进程收集元素到根进程上面。元素是根据接收到的进程的秩排序的。
MPI_Gather( void * send_data, int send_count, MPI_Datatype send_datatype, void * recv_data, int recv_count, MPI_Datatype recv_datatype, int root, MPI_Comm communicator)
在MPI_Gather中,只有根进程需要一个有效的接收缓存。所有其他的调用进程可以传递NULL给recv_data。另外,别忘记 recv_count 参数是从每个进程接收到的数据数量,而不是所有进程的数据总量之和。
计算平均数 int main (int argc, char **argv) { MPI_Init(NULL , NULL ); int world_size; MPI_Comm_size(MPI_COMM_WORLD, &world_size); int world_rank; MPI_Comm_rank(MPI_COMM_WORLD, &world_rank); float *rand_nums; if (world_rank == 0 ) { rand_nums = malloc (sizeof (float ) * total_size); for (int i = 0 ; i < total_size; i++) rand_nums[i] = (float )rand() / RAND_MAX * 100 ; } float *sub_nums = malloc (sizeof (float ) * total_size / world_size); MPI_Scatter(rand_nums, total_size / world_size, MPI_FLOAT, sub_nums, total_size / world_size, MPI_FLOAT, 0 , MPI_COMM_WORLD); float average = compute_avg(sub_nums, total_size / world_size); float *sub_avgs; if (world_rank == 0 ) { sub_avgs = malloc (sizeof (float ) * world_size); } MPI_Gather(&average, 1 , MPI_FLOAT, sub_avgs, 1 , MPI_FLOAT, 0 , MPI_COMM_WORLD); if (world_rank == 0 ) { float avg = compute_avg(sub_avgs, world_size); printf ("average is: %f\n" , avg); } MPI_Finalize(); return 0 ; }
将 total_size 个数据均分到 world_size 个进程上执行,每个进程需要分配 total_size / world_size 个数据,注意 MPI_Scatter 中的 send_count 和 recv_count 是 Root 分发到每个进程的数据量,也即 total_size / world_size。MPI_Gatter 中的 send_count 和 recv_count 是 Root 需要从每个进程收集的数据量,也即 1。
MPI_Allgether 不同于以上一对多或者多对一的通信模式,MPI_Allgather 是一个多对多的通信模式。对于分发在所有进程上的一组数据来说,MPI_Allgather会收集所有数据到所有进程上。MPI_Allgather相当于一个MPI_Gather操作之后跟着一个MPI_Bcast操作。
跟MPI_Gather一样,每个进程上的元素是根据他们的秩为顺序被收集起来的,只不过这次是收集到了所有进程上面。
MPI_Allgather( void * send_data, int send_count, MPI_Datatype send_datatype, void * recv_data, int recv_count, MPI_Datatype recv_datatype, MPI_Comm communicator)
和 MPI_Gatter 一样,只是没有 Root 参数来决定根节点了。
float average = compute_avg(sub_nums, total_size / world_size);float *sub_avgs = malloc (sizeof (float ) * world_size);MPI_Allgather(&average, 1 , MPI_FLOAT, sub_avgs, 1 , MPI_FLOAT, MPI_COMM_WORLD); float avg = compute_avg(sub_avgs, world_size);printf ("average is: %f on rank %d\n" , avg, world_rank);
如上,每个节点都能够计算平均值了。
MPI Reduce and Allreduce 归约是函数式编程中的经典概念。数据归约包括通过函数将一组数字归约为较小的一组数字。 例如,假设我们有一个数字列表 nums = [1,2,3,4,5]。 用 sum 函数归约此数字列表将产生 sum(nums) = 15。 类似地,乘法归约将产生 multiply(nums) = 120。
在一组分布式数字上应用归约函数可能非常麻烦。幸运的是,MPI 有一个方便的函数,MPI_Reduce,它将处理程序员在并行程序中需要执行的几乎所有常见的归约操作。
与 MPI_Gather 类似,MPI_Reduce 在每个进程上获取一个输入元素数组,并将输出元素数组返回给根进程。 输出元素包含减少的结果。
MPI_Reduce( void * send_data, void * recv_data, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm communicator)
send_data 参数是每个进程都希望归约的 datatype 类型元素的数组。 recv_data 仅与具有 root 秩的进程相关。 recv_data 数组包含归约的结果,大小为sizeof(datatype)* count。 op 参数是您希望应用于数据的操作,包括 MPI_MAX、MIN、SUM、PROD(乘)等。
float average = compute_avg(sub_nums, total_size / world_size);float sum = 0 ;MPI_Reduce(&average, &sum, 1 , MPI_FLOAT, MPI_SUM, 0 , MPI_COMM_WORLD); if (world_rank == 0 ) { printf ("average is %f\n" , sum / world_size); }
将每个节点的局部平均值加起来给 Rank 0,然后在 Rank 0 上输出结果。如果在其他 Rank 中输出,结果为 0,因为数据不会写入其他进程的内存空间。
MPI_Allreduce 将归约值并将结果分配给所有进程。函数原型和 MPI_Reduce 一样,只是没有 Root。
接下来,我们使用该函数计算标准差 。首先,我们需要计算每个节点的局部和,然后通过该函数,使得每个节点都能得到全局和。有了全局和也就有了平均值。然后我们计算每个元素和平均值差值的平方,再次规约得到所有平方的和,最后计算标准差。
float average = compute_avg(sub_nums, total_size / world_size);float average_sum = 0 ;MPI_Allreduce(&average, &average_sum, 1 , MPI_FLOAT, MPI_SUM, MPI_COMM_WORLD); float mean = average_sum / world_size; float local_sq_diff = 0 ;for (int i = 0 ; i < total_size / world_size; i++) { local_sq_diff += (sub_nums[i] - mean) * (sub_nums[i] - mean); } float stddev_sum; MPI_Reduce(&local_sq_diff, &stddev_sum, 1 , MPI_FLOAT, MPI_SUM, 0 , MPI_COMM_WORLD); if (world_rank == 0 ) { printf ("stddev is %f\n" , sqrt (stddev_sum / total_size)); }
Groups and Communicators 通讯器 通讯器是 MPI 中用于描述一组进程的对象,它提供了一个上下文和一个通信域,进程可以在这个域内进行通信操作。每个通讯器都有一个唯一的上下文,用于确保不同通讯器中的通信不会互相干扰。
上下文隔离 :通讯器定义了一个独立的通信上下文,在不同的通讯器中,即使使用相同的消息标签和来源,消息也不会混淆。这种上下文隔离使得可以在同一程序中独立地管理不同的通信域。通信操作 :所有的点对点通信(如 MPI_Send 和 MPI_Recv)和集合通信(如 MPI_Bcast 和 MPI_Reduce)操作都需要一个通讯器。默认通讯器 :MPI 初始化时会创建一个包含所有进程的默认通讯器 MPI_COMM_WORLD,这是最常用的通讯器。
MPI_Comm_split( MPI_Comm comm, int color, int key, MPI_Comm* newcomm) MPI_Comm_dup(MPI_Comm comm, MPI_Comm *newcomm); MPI_Comm_free(MPI_Comm *comm); MPI_Comm_create(MPI_Comm comm, MPI_Group group, MPI_Comm *newcomm);
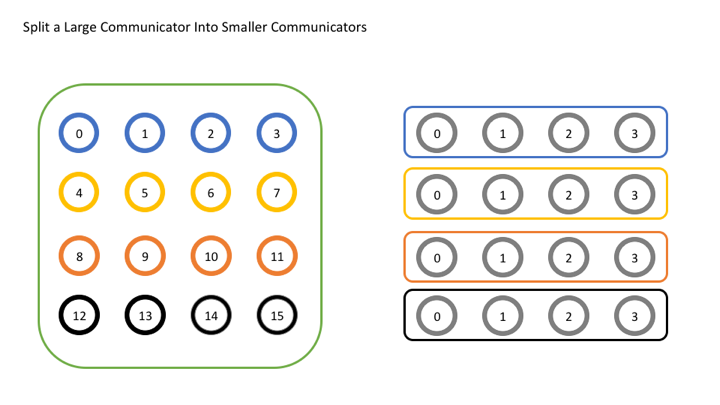
我们希望按如下方式划分网格,形成 4 个新的通讯器。
代码如下:
int world_rank, world_size;MPI_Comm_rank(MPI_COMM_WORLD, &world_rank); MPI_Comm_size(MPI_COMM_WORLD, &world_size); int color = world_rank / 4 ; MPI_Comm row_comm; MPI_Comm_split(MPI_COMM_WORLD, color, world_rank, &row_comm); int row_rank, row_size;MPI_Comm_rank(row_comm, &row_rank); MPI_Comm_size(row_comm, &row_size); printf ("WORLD RANK/SIZE: %d/%d \t ROW RANK/SIZE: %d/%d\n" , world_rank, world_size, row_rank, row_size); MPI_Comm_free(&row_comm);
组 组是 MPI 中描述进程集合的对象,它仅仅定义了一组进程的成员,而不提供通信上下文。组是静态的,表示一组进程的固定成员列表。
MPI使用组(MPI_Group)来管理通信器中的进程集合。
组的操作类似于集合论,包括并集和交集。
通讯器可以用来创建组,然后组再进行一些如下操作,又可以用来创建新的通讯器。
MPI_Comm_group( MPI_Comm comm, MPI_Group* group) MPI_Group_union( MPI_Group group1, MPI_Group group2, MPI_Group* newgroup) MPI_Group_intersection( MPI_Group group1, MPI_Group group2, MPI_Group* newgroup) MPI_Comm_create_group( MPI_Comm comm, MPI_Group group, int tag, MPI_Comm* newcomm) MPI_Group_incl( MPI_Group group, int n, const int ranks[], MPI_Group* newgroup) MPI_Group_excl( MPI_Group group, int n, const int ranks[], MPI_Group *newgroup);