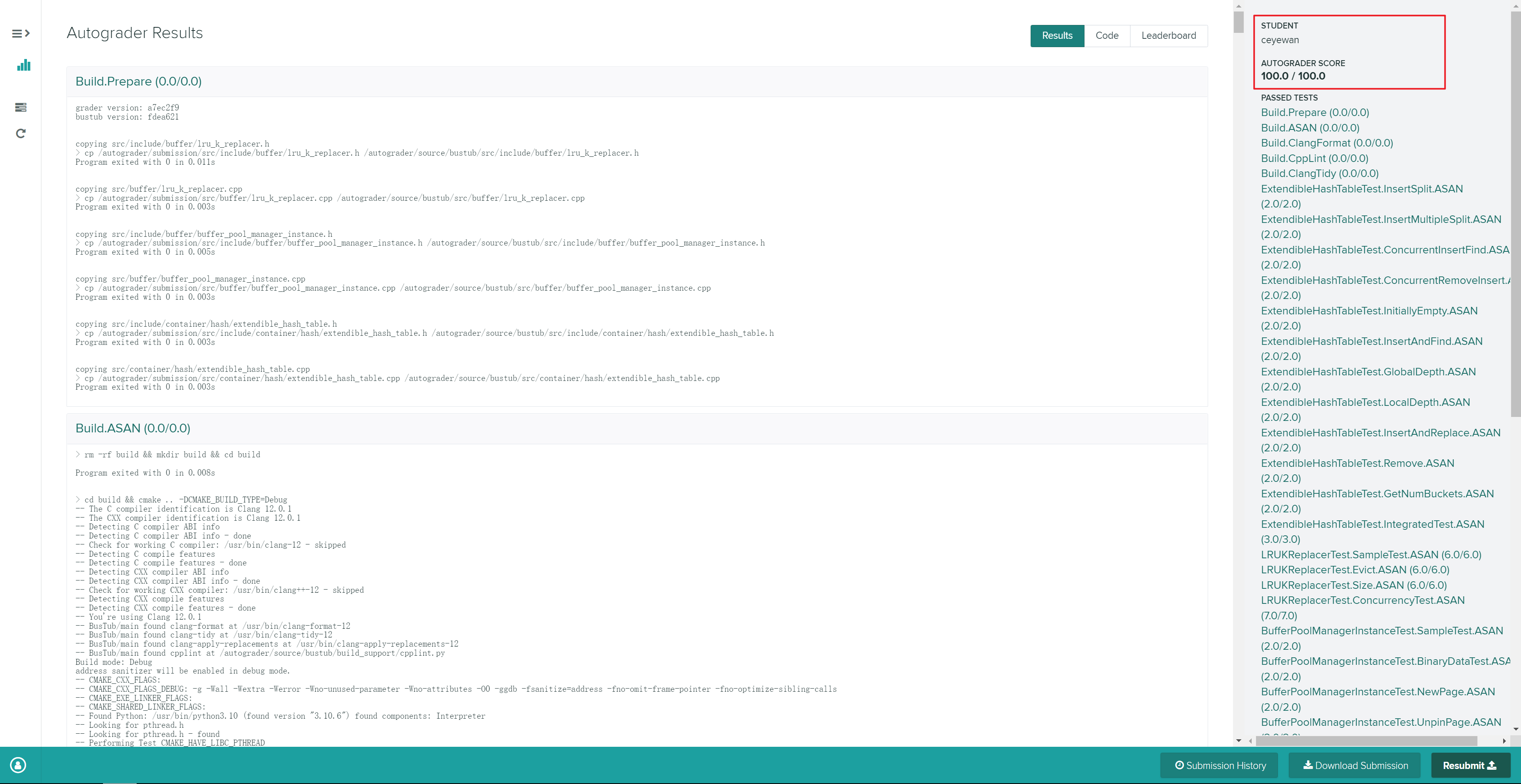
实验说明
https://15445.courses.cs.cmu.edu/fall2022/project1/
这个项目是实现一个 buffer pool,缓冲池负责将物理页在主内存和磁盘之间来回移动,从而允许 DBMS 支持大于系统可用内存量的数据库。系统通过唯一标识符 page_id_t 向缓冲池请求一个页面,缓冲池从内存或者磁盘中检索该页面后返回给系统。
缓冲池的实现需要是线程安全的,也就是说支持并发操作。
Extendible Hash Table
参考资料:https://www.geeksforgeeks.org/extendible-hashing-dynamic-approach-to-dbms/
可拓展哈希的结构如下:
- 目录:存储指向桶的指针。
- 桶:哈希键值对,如果局部深度小于全局深度时,一个桶可能包含不止一个指针指向它。
- 全局深度:和目录相关联,也就是哈希后取的比特数。
- 局部深度:和桶关联,表示桶中的数据是哈希后取低
x 位得到的。
最复杂的就是插入数据了,流程如下:
- 将
key 哈希后,如果全局深度为 n,那么取低 n 位比特。比如 n = 4 时,哈希出来的结果为 xxx0011,表示这个 key 应该存储到 dir[0011] 指向的桶中。
- 如果桶已经满了,那么比较全局深度和局部深度的大小。
- 如果相等,
dir 目录项扩容一倍,全局深度相应增加 1 。新增的那些 dir[i] 指向 dir[i - PreDirSize]。比如开始时全局深度为 2,那么 dir 大小为 4,扩容后大小为 8,其中 dir[5] 应该指向 dir[1]。因为 5 中对应的 key 哈希值低 3 位为 101,在还没扩容之前,低 2 位为 01。也就意味着,现在本该存储在 dir[5] 中的 key 之前存在 dir[1] 中,我们直接将 dir[5] = dir[1],共用。当全局深度比局部深度大 n 时,有 2^n 个 dir 目录项共用这个桶。
dir 扩容后,再次尝试插入,这个时候桶还是满的,不过局部深度比全局深度小。- 如果局部深度比全局深度小,我们将局部深度增加
1 ,比如原来是 2 ,现在变成 3,那么里面的 key 哈希值低两位都是相同的,第 3 位的 0 和 1 可以把这里面的 key 分成两部分。
- 分完之后,让
dir 中低 3 位是 0xx 和 1xx 的目录项分别指向拆分后的桶。
template <typename K, typename V>
void ExtendibleHashTable<K, V>::Insert(const K &key, const V &value) {
latch_.lock();
while (true) {
size_t index = this->IndexOf(key);
bool flag = dir_[index]->Insert(key, value);
if (flag) {
break;
}
if (GetLocalDepthInternal(index) != GetGlobalDepthInternal()) {
RedistributeBucket(dir_[index]);
} else {
global_depth_++;
size_t dir_size = dir_.size();
for (size_t i = 0; i < dir_size; i++) {
dir_.emplace_back(dir_[i]);
}
}
}
latch_.unlock();
}
|
下面是桶分裂函数,如果之前有 2n 个 dir 目录项指向这个桶,分裂后两个桶分别有 n 个目录项:
template <typename K, typename V>
auto ExtendibleHashTable<K, V>::RedistributeBucket(std::shared_ptr<Bucket> bucket) -> void {
bucket->IncrementDepth();
int depth = bucket->GetDepth();
num_buckets_++;
std::shared_ptr<Bucket> p(new Bucket(bucket_size_, depth));
size_t preidx = std::hash<K>()((*(bucket->GetItems().begin())).first) & ((1 << (depth - 1)) - 1);
for (auto it = bucket->GetItems().begin(); it != bucket->GetItems().end();) {
size_t idx = std::hash<K>()((*it).first) & ((1 << depth) - 1);
if (idx != preidx) {
p->Insert((*it).first, (*it).second);
bucket->GetItems().erase(it++);
} else {
it++;
}
}
for (size_t i = 0; i < dir_.size(); i++) {
if ((i & ((1 << (depth - 1)) - 1)) == preidx && (i & ((1 << depth) - 1)) != preidx) {
dir_[i] = p;
}
}
}
|
LRU-K Replacement Policy
LRU-K 替换策略负责跟踪缓冲池中的页使用情况。lRU-K 算法记录最近 K 次访问,如果不满 K 次用 +inf 填充,当需要驱逐一个 frame 帧时,我们选择往前第 K 次访问的时间戳最小的那个帧访问。
auto LRUKReplacer::Judge(frame_id_t s, frame_id_t t) -> bool {
if (hash_[s].time_.size() < k_ && hash_[t].time_.size() == k_) {
return true;
}
if (hash_[s].time_.size() == k_ && hash_[t].time_.size() < k_) {
return false;
}
return hash_[s].time_.front() < hash_[t].time_.front();
}
auto LRUKReplacer::Evict(frame_id_t *frame_id) -> bool {
*frame_id = -1;
for (const auto &kv : hash_) {
if (kv.second.evictable_) {
if (*frame_id == -1 || Judge(kv.first, *frame_id)) {
*frame_id = kv.first;
}
}
}
if (*frame_id != -1) {
hash_.erase(*frame_id);
curr_size_--;
return true;
}
return false;
}
struct Frameinfo {
bool evictable_{false};
std::queue<size_t> time_;
};
std::unordered_map<frame_id_t, struct Frameinfo> hash_;
|
RecordAccess 方法,为帧添加一次访问时间,如果超过 k 了需要删除最早的那个,并且每次调用这个方法我们将 current_timestamp_++ 表示时间的流逝。
SetEvictable 方法,设置 evict 的值,如果从 false 到 true,那么 curr_size_ 需要增加,反之,需要减少。
Remove 方法,注意 evictable_ == false 不能删除时,需要抛出异常,throw "Remove a non-evictable frame!";。
Buffer Pool Manager Instance
缓冲池管理器 BufferPoolManagerInstance 负责从 DiskManager 获取数据库页并将其存储在内存中和将脏页写入磁盘。它使用 ExtendibleHashTable 作为将 page_id 映射到 frame_id 的哈希表,使用 LRUKReplace 跟踪 page 对象的访问时间,在需要释放一个帧给新的 page 腾出空间时由 LRUKReplace 来决定驱逐哪个 page。
NewPgImp 方法,先从 free_list_ 查找空闲帧,没找到再调用 replacer_.Evict 查找空闲帧,找到的帧如果是脏页需要写回数据。调用 AllocatePage() 分配 page_id ,将分配的 frame 插入 replacer_ 和 page_table_,并设置一些元数据。
auto BufferPoolManagerInstance::FetchPgImp(page_id_t page_id) -> Page * {
frame_id_t frame_id = -1;
if (page_table_->Find(page_id, frame_id)) {
replacer_->RecordAccess(frame_id);
replacer_->SetEvictable(frame_id, false);
pages_[frame_id].pin_count_ += 1;
auto p = &pages_[frame_id];
return p;
}
if (!free_list_.empty()) {
frame_id = free_list_.front();
free_list_.pop_front();
} else if (replacer_->Evict(&frame_id)) {
if (pages_[frame_id].IsDirty()) {
disk_manager_->WritePage(pages_[frame_id].GetPageId(), pages_[frame_id].GetData());
}
page_table_->Remove(pages_[frame_id].GetPageId());
} else {
latch_.unlock();
return nullptr;
}
page_table_->Insert(page_id, frame_id);
pages_[frame_id].page_id_ = page_id;
pages_[frame_id].pin_count_ = 1;
pages_[frame_id].is_dirty_ = false;
pages_[frame_id].ResetMemory();
disk_manager_->ReadPage(page_id, pages_[frame_id].GetData());
replacer_->RecordAccess(frame_id);
replacer_->SetEvictable(frame_id, false);
auto p = &pages_[frame_id];
latch_.unlock();
return p;
}
|
UnpinPgImp 方法,将 pin_count_--,如果变成 0 了需要 SetEvictable。
FlushAllPgsImp 方法遍历 frame_id,从 page 中得到 page_id,如果这一对键值对在 page_table_ 中,说明是合法数据,需要 Flush 。
DeletePgImp 方法,需要考虑是否 pin 了,也就是 evictable,如果可以删,那么 replacer_、free_list_、page_table_
结果