概述
本实验是在数据库系统中实现一个索引。索引负责快速数据检索,而不必搜索数据库表中的每一行,为快速随机查找和高效访问有序记录提供了基础。
在这个 project 中需要实现 B+ 树动态索引结构。它是一个平衡的树,其中 internalpages 指导搜索,leafpages 包含实际的数据。因为树形结构是动态增长和收缩的,所以需要处理 split 和 merge 的逻辑。在这个实验中,我们主要需要实现 B+Tree 的插入、删除、查找这三种操作,迭代器和并发操作。
Task #1 - B+Tree Pages
B+树有两种页,一种是内部页 InternalPage,还有一种是叶子页 LeafPage。其中页中数据全部都是 k-v 对,对于内部页来说 v 是子页的 page_id,对于叶子页来说 v 是 RID,是 B+ 树中存储的唯一的数据。
LeafPage 有 m 对 k-v 对,而 InternalPage 有 n 个 k, n + 1 个 v。其中 array_[i].second 子树中的元素 rid 满足 array_[i].key <= rid < array_[i + 1].key ,所以 array_[0] 没有 key。
MappingType array_[1] 是 flexible array,在为类分配空间时,除了已经使用的空间, flexible array 会自动填充剩下的空间。因此,它只能出现在类的最后一个成员。
由于数据在 page 中均为有序排列,在查找时,最好使用二分查找。
Task2 B+Tree Data Structure
Search
在 B+ 树中,递归的查找,找到 key 所在的 leafpage,并从 page 中二分查找到 key。
在实现中,对 page 的 new、fetch、unpin 等操作,均需要使用 Project 1 中实现 BufferPoolManager 来实现。
Insert
前面的步骤和 Search 相同,找到 key 要插入的 leafpage 和 index。插入后,如果没满,结束。如果满了,new 一个新的 page,将一半数据转移到 new page 中,更新 next_page_id 用于维护 Iterator。获取 parent page,将 new page 插入 parent page 中,如果 parent page 满了。利用额外空间将数据插入后,调用分裂,递归的插入 parent page 的 parent 中。
这里我们对 leafpage 和 internalpage 的处理是不同的,leafpage 满 maxsize 就调用分裂,也就是说 leafpage 的 size 最大为 maxsize - 1。而 internalpage 的 size 可以是 maxsize(因为如果不可以,maxsize 为 3 时调用分裂,一定会分裂出一个 size 为 1 的 page,这是不被允许的)。因此我们在向 internalpage 插入数据时,可能会溢出,需要额外空间辅助,在额外空间插入后调用分裂。
注意插入可能导致递归分裂,一直到 root page,root page 分裂时需要一个 new 一个新的 rootpage。
Delete
前面的步骤和 Search 相同,找到 key 的 leafpage 和 index。删除后,如果够 minsize 就结束。如果不够,需要查找 bother page,如果可以和 bother page 合并,那么合并,合并后父页也需要调用删除。如果不能合并,那么说明 bother page 比 minsize 大,调用重新分配函数,从 bother page 中拿一个 k-v 对给 page。需要分类讨论 bother page 在 page 的前还是后。
注意删除可能导致递归合并,一直到 root page,还需要考虑 root page 的最小值不受 minsize 约束。如果 root page 同时还是 leafpage 那么最小可以是 1 ,删除后需要 delete page。如果 root page 不是 leafpage 那么最小可以是 2,删除后为 1,无效 internalpage,需要删除,并将 childpage 设为 rootpage。
实现难度较大,细节很多很多。
Task #3 - Index Iterator
迭代器的实现比较简单。其实迭代器就是一个封装了一些方法的“指针”。begin() 我们使用 B+ 树的第一个 key 来构造即可;begin(key) 使用特定的 key 来构造;end() 使用最后一个 key 后一个来构造即可。也就是说,Iterator 由 leafpage_id 和 index 两个值决定。++ 运算只需要 index++ 即可。如果到了最后一个 index 就通过 next_page_id 拿到后一个 leafpage_id 并将 index 设为 0。
Task #4 - Concurrent Index
latch crabbing 的意思是,像螃蟹一样,移动一只脚,放下,移动另一只脚,再放下。先锁住 parent page,然后锁住 child page,在 child page 是安全的情况下,释放 parent page。
Search
像上面一样,不断操作,最终只拥有 leafpage 的锁。
Insert & Delete
如果 child page 安全,就释放 parent page 的锁。安全的定义是,在插入时,child page 插入后不会分裂;在删除时,child page 删除后不会合并。就可以释放 parent page 的锁了。
最终,findleafpage 会拿到一串锁,我们使用 transaction 来管理这些锁住的 page。在插入和删除时可以使用,最后统一释放。
优化方案之一:读锁和写锁的使用。
优化方案之二:乐观锁,我们假定不会触发合并或者分裂,Insert 和 Delete 像 Search 一样获得锁。最后发现会触发这些操作,就重来一次,按照上面讲的悲观锁。
在线测试时,有一个测试案例一直过不了,于是我把 findleafpage 加了一把锁,可以通过。在 20 年的测试中,两种方案都能通过。在测试中,加大锁的方案速度不仅没慢,反而比不加锁更快,这就很迷惑了,可能是反而降低了锁冲突吧。
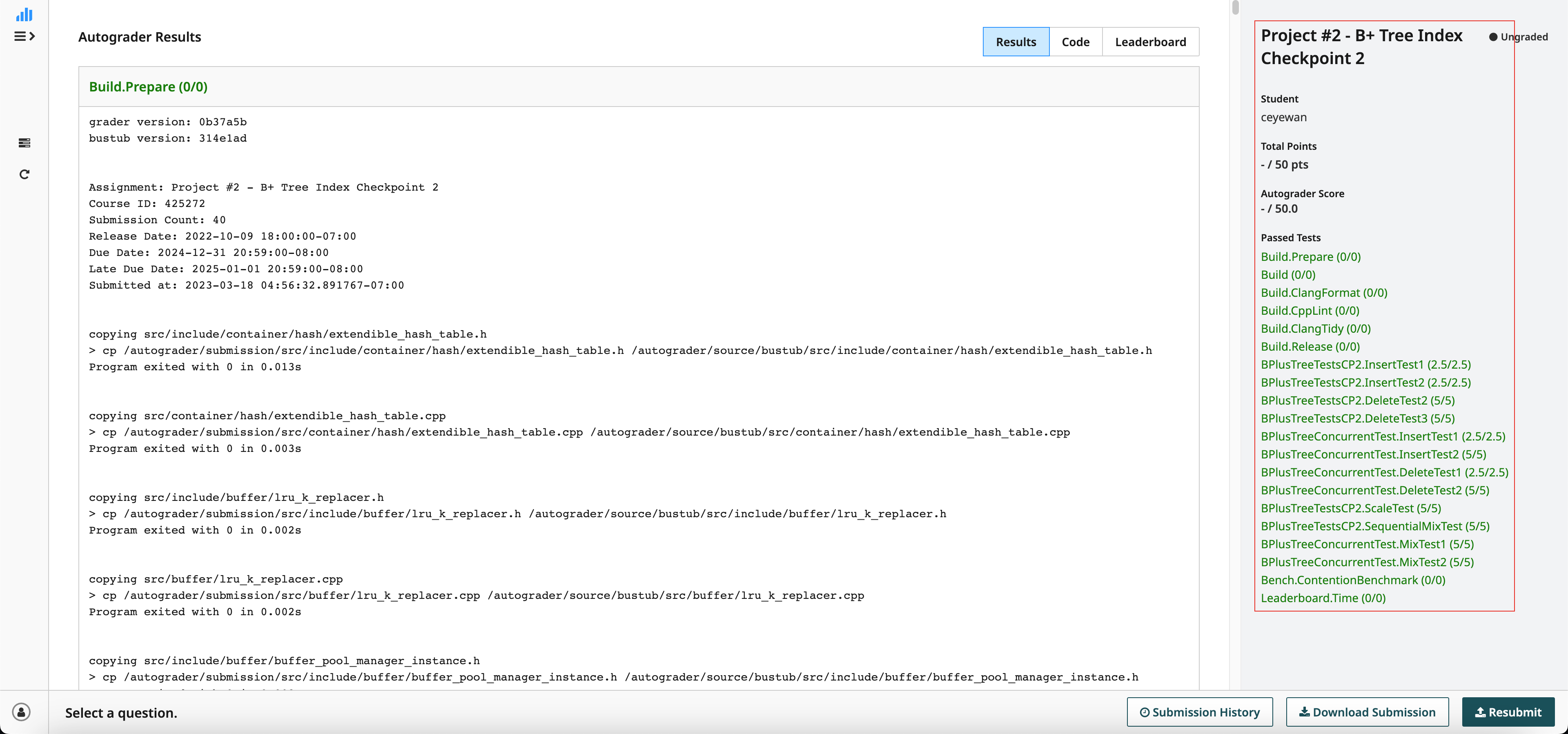
结果
Checkpoint 1:
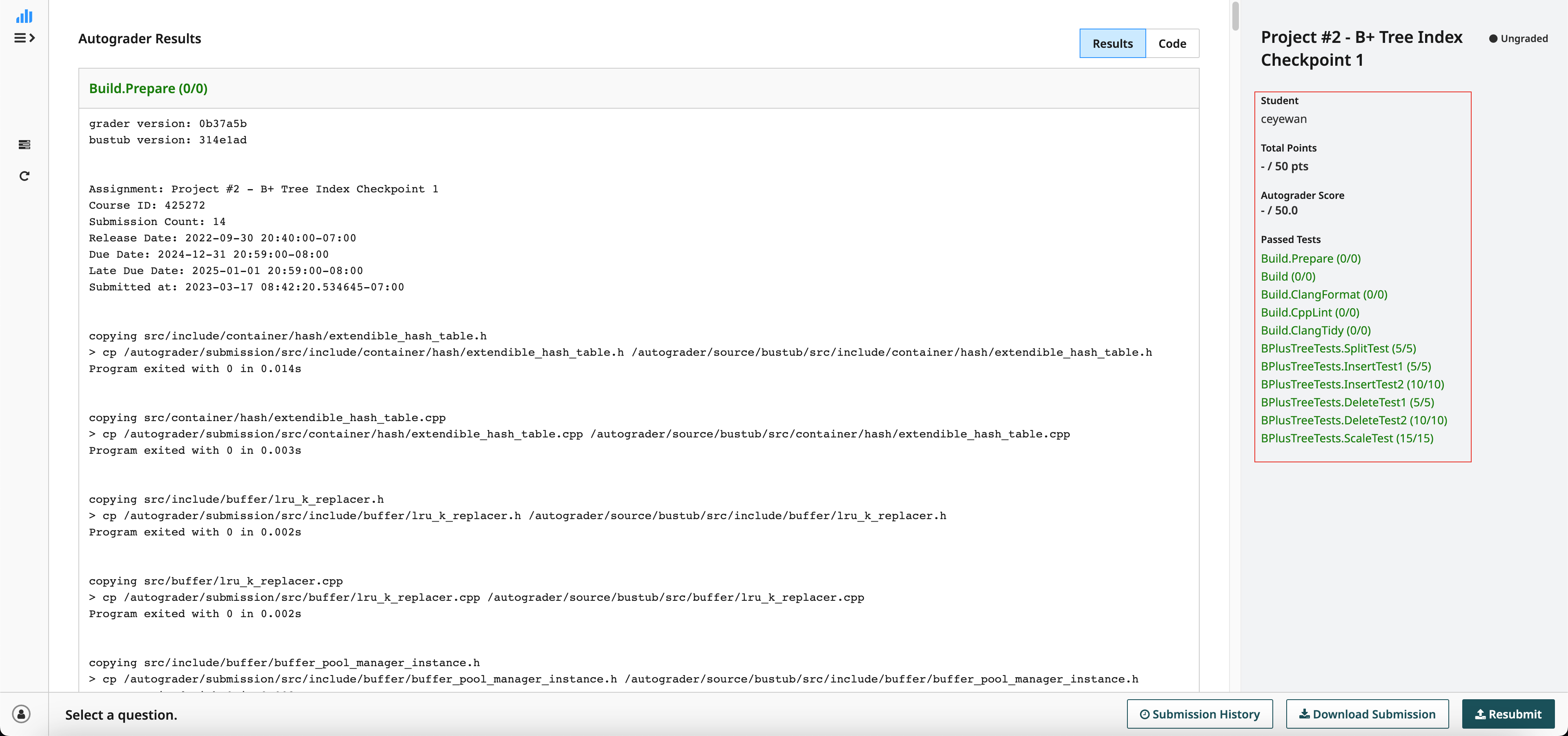
Checkpoint 2: