实验目的
在 ubuntu 下实现内核 HOOK 功能,观察 HOOK 的系统调用。
实验环境
uname -a |
实验原理
基本概念
Hook 技术又叫做钩子函数,在系统没有调用该函数之前,钩子程序就先捕获该消息,钩子函数先得到控制权,这时钩子函数既可以加工处理(改变)该函数的执行行为,还可以强制结束消息的传递。简单来说,就是把系统的程序拉出来变成我们自己执行代码片段。我们通过修改 sys_call_table 来修改函数的执行行为。
得到 sys_call_table 的内存位置
我们使用暴力搜索地址的方法来查找 sys_call_table 的地址。PAGE_OFFSET 是内核内存空间的起始地址,并且因为 sys_close 是导出函数,我们可以直接得到他的地址(它的系统调用号 __NR_close)。sys_call_table 是一个一维数组,当我们遍历每一种可能时,如果 entry[__NR_close] == (unsigned long *)sys_close,说明 entry 正好就是系统调用表。
unsigned long **get_sys_call_table(void) { |
关闭写保护
写保护指的是写入只读内存时出错。这个特性可以通过 CR0 寄存器控制:开启或者关闭,只需要修改一个比特,也就是从 0 开始数的第 16 个比特。我们可以使用 read_cr0/write_cr0 来读取/写入 CR0 寄存器,免去我们自己写内联汇编的麻烦。
void disable_write_protection(void) { |
修改 sys_call_table
首先,将真实的系统调用备份为 real_open、real_unlik、real_unlinkat,并且将系统调用修改为我们自己的函数。这样,在调用系统调用号为 __NR_open 的系统调用时,会调用我们的 fake_open 而不是 real_open。
disable_write_protection(); |
恢复 sys_call_table
disable_write_protection(); |
注意
这里我们的系统调用不能是直接写一个函数就行了,而要写一个内核模块,这样才能被系统在任何情况下调用。用我们的模块替换掉系统模块。从而实现 hook(或者说劫持)。
实验内容和步骤
下载源码:
git clone https://github.com/jha/linux-kernel-hook.git |
分析源码
最主要的代码就是 module.c,创建一个内核模块。这个模块的 __init 函数主要是 sys_hook_init 和 sys_hook_add64 函数。这样,注册模块时就可以将我们的 hook 函数注册进内核。
hooks.c 和 hook.h 就是写了一个 mkdir_hook 函数,作用就是劫持系统调用 mkdir 转而调用我们的 hook_mkdir,而我们的 mkdir 做的就是打印一条日志信息后调用 sys_mkdir。
asmlinkage int mkdir_hook(const char *path, int mode) { |
sys_hook.c 和 sys_hook.h 主要实现了下面这几个函数,用来方便的实现 hook 函数的增添、删除等操作。
struct sys_hook *sys_hook_init(uintptr_t k32, uintptr_t k64); |
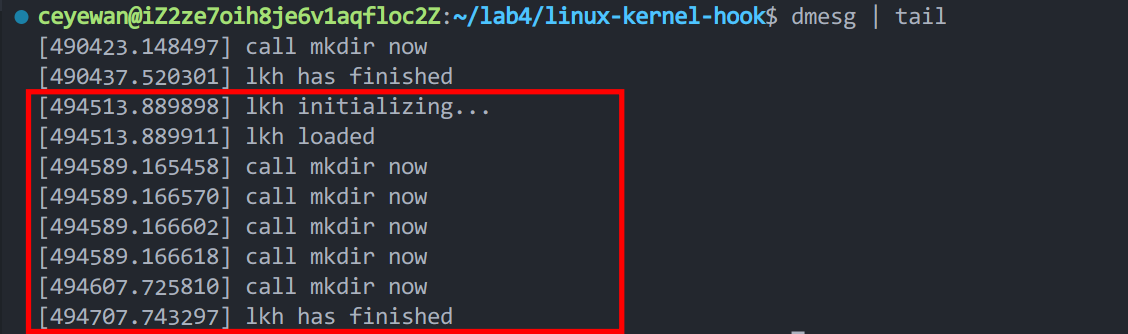
执行代码
make # 编译生成 lkh.ko |
将 mkdir hook 为 rmdir
这样没什么意思,我们要搞点乱的。这里我选择 hook(劫持) mkdir 这个系统调用到 rmdir 这个系统调用。这样从而实现虽然是调用 mkdir 但是实际上调用了 rmdir 的现象。
首先,修改一些代码:
// module.c 在下面这一行中添加 rmdir 这一行,第三个参数没什么用,所以我们就不写了 |
只需要修改这么一点点,我们就可以得到一种截然不同的结果:
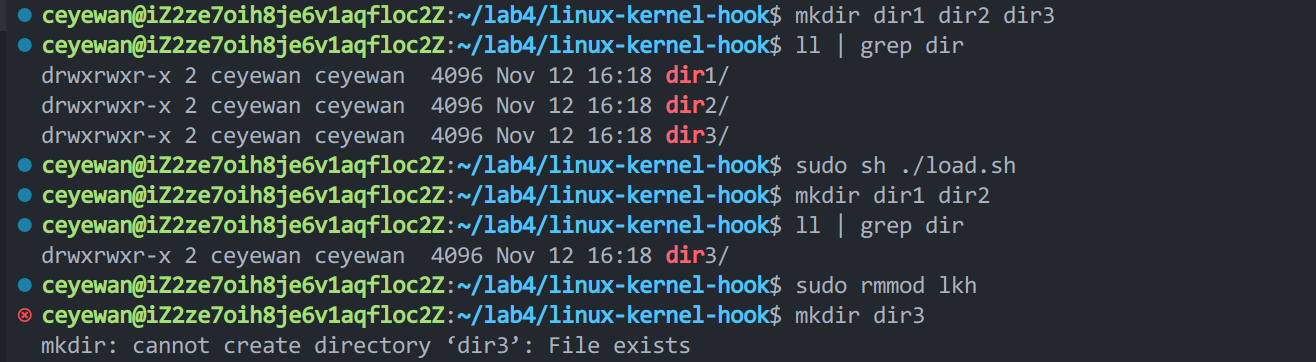
可以看到我先创建了 dir1 dir2 dir3 这 3 个文件夹,然后加载模块到内核,加载后执行 mkdir dir1 dir2 不仅没有报 File exists 的错,反而将这两个文件夹删除了。在将模块移除后,mkdir 又恢复了正常。
思考与总结
KERN_ALERT 的作用?
这是一种消息打印的级别,KERN_ALERT 对于的级别是 1,而我们另一个用到 KERN_INFO 的级别是 6。数字越小面积别越高。printk 输出跟输出的日志级别有关系,当输出日志级别比控制台的级别高时,就会显示在控制台上,当比控制台低时,则会记录在 /var/log/message 中。
本实验中提到了几种获取 sys_call_table 地址的方法,请思考它们的优缺点?
方法一:从 /boot/System.map 中读取。打开文件,将其中的内容拷贝下来就可以了,如 Hooking the Linux System Call Table 所说:
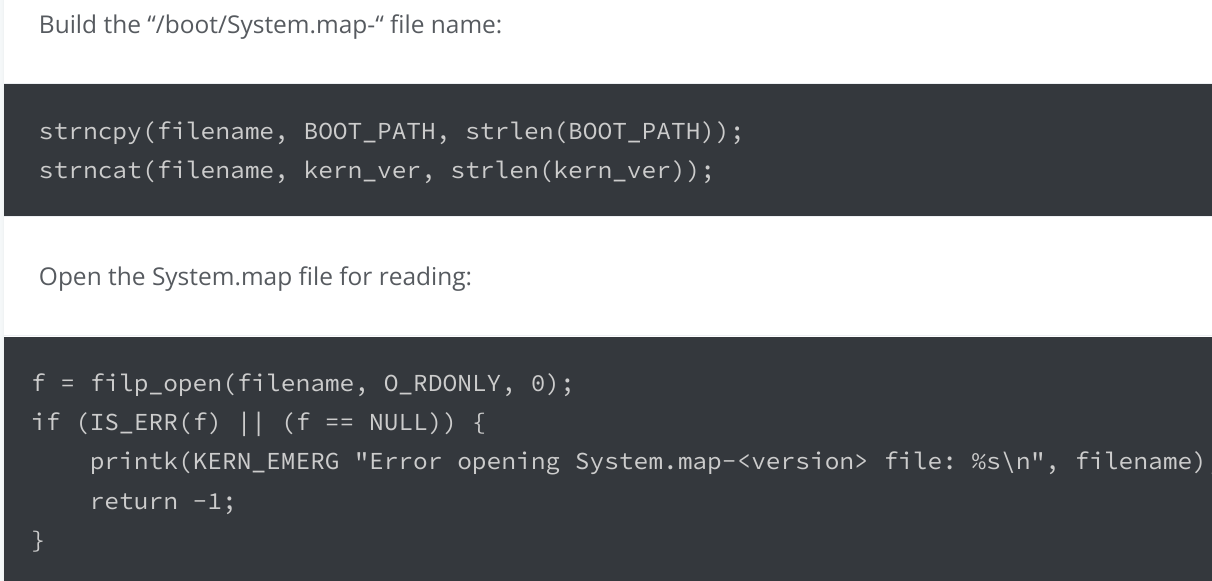
方法二:从使用了 sys_call_table 的某些未导出函数的机器码里面进行特征搜索。Kernel-Land Rootkits。难度较高。

方法三:暴力搜索,就像最上面写的算法,优点是简单理解操作,缺点是时间复杂度比较高。