CUDA 硬件和开发环境
GPU 硬件简介
GPU,即图形处理器,与 CPU 对应。一个典型的 CPU 拥有少数几个快速的计算核心,而一个典型的 GPU 拥有几百到几千个不那么快速的计算核心。CPU 中有更多的晶体管用于数据缓存和流程控制,但 GPU 中有更多的晶体管用于算术逻辑单元。CPU 和 GPU 的硬件架构区别如下。
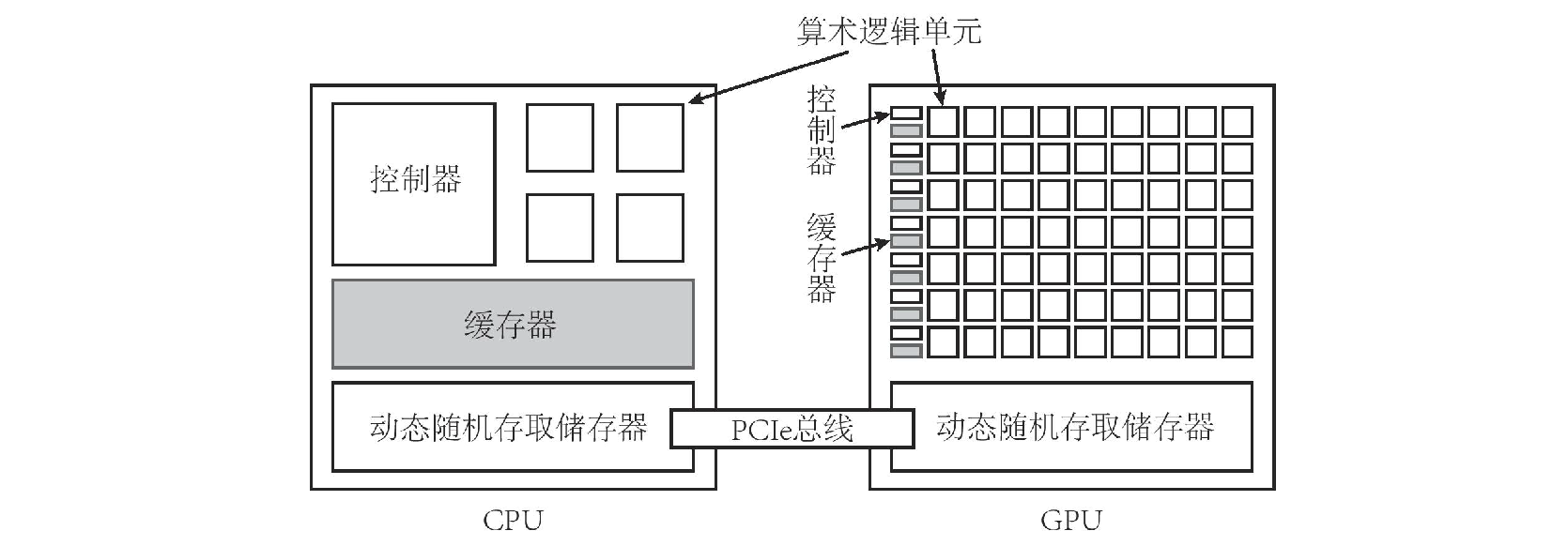
在 CPU-GPU 异构计算平台中,通常将起控制作用的 CPU 称为主机(host),将起加速作用的 GPU 称为设备(device)。每一款 GPU 都有一个用以表示其“计算能力”(Compute Capability)的版本号,版本号越大的 GPU 架构(Architecture)越新。主计算能力为 6 时,对应 Pascal 架构。
CUDA 程序开发工具
- CUDA。用于 NVIDIA GPU 编程,根据基于的语言可分为 CUDA C 和 CUDA C++。
- 开发环境配置。在安装好了 GPU 驱动后,安装支持的 CUDA Toolkit 开发包。
- 使用
nvidia-smi命令检查与设置设备。其中 Compute M 分为默认模式或独占进程模式。 - CUDA 官方手册,CUDA C++ Programming Guide 和 CUDA C++ Best Practices Guide。
CUDA 中的线程组织
编写如下程序:
|
使用如下命令编译执行:
➜ nvcc -O3 -arch=sm_61 -o gpu hello.cu // -arch=sm_61 指定 GPU 架构 |
其中,__global__ 表明这是一个核函数,在设备中执行。其中,grid_size 和 block_size 分别表示核函数的网格大小和线程块大小,一般我们用一维或者二维形式。上面的程序表明线程块大小为 2 * 4,也就是说这 8 个线程可以同时执行,表现出来就是输出顺序不一定。而网格为 1 * 2 个,一次只能执行一个网格,表现为要么输出完 (0, 0) 网格后输出 (0, 1),或者反之。
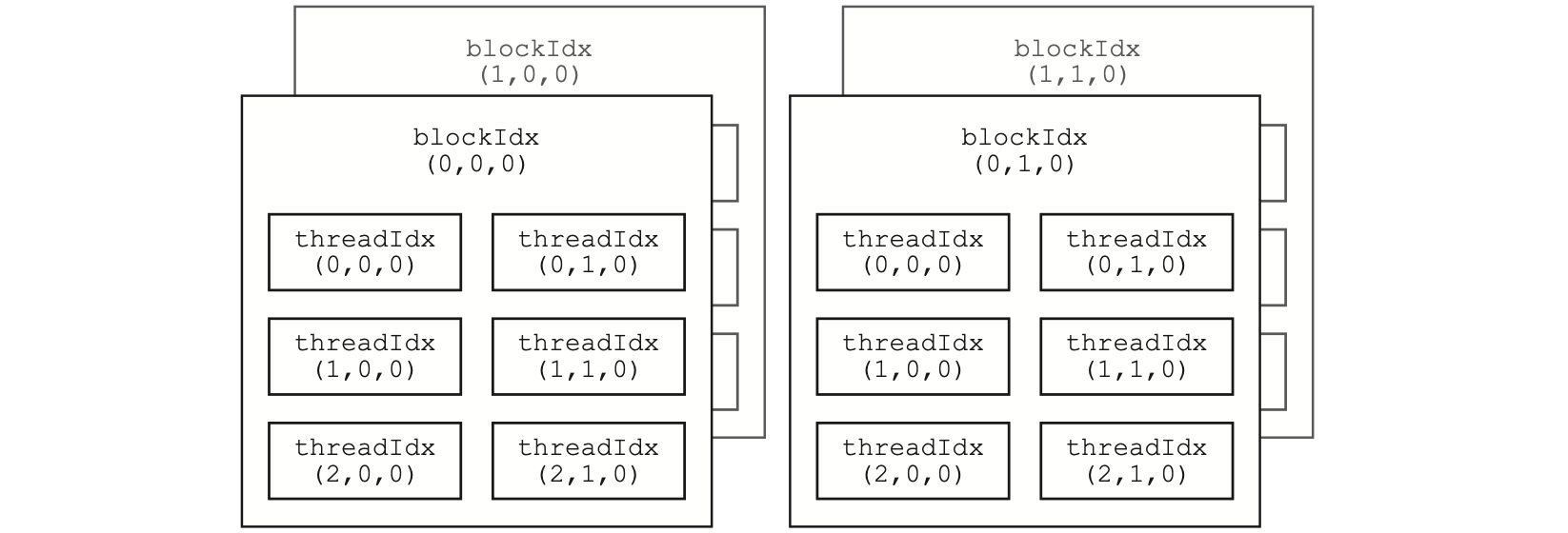
需要注意的是,线程块大小在 x、y 和 z 这 3 个方向的最大允许值分别为 1024、1024 和 64。但是,一个线程块最多只能有 1024 个线程。即 blockDim.x、blockDim.y 和 blockDim.z 的乘积不能大于 1024。
获得 GPU 加速的关键
为 CUDA 程序和 C 程序计时
使用基于 CUDA 事件的计时方式,为 CUDA 代码计时。
cudaEvent_t start, stop; // 创建两个 CUDA 时间并初始化 |
使用 clock() 对 C 代码计时。
clock_t start = clock(); |
几个影响 GPU 加速的关键因素
- 数据传输的比例:要获得可观的 GPU 加速,必须尽量缩减数据传输所花时间的比例。这是因为连接 CPU 和 GPU 内存的 PCIe 总线带宽相比于 GPU 计算核心和设备内存之间数据传输带宽来说很低。
- 算术强度:算术强度指的是其中算术操作的工作量与必要的内存操作的工作量之比。因此,读写次数少而计算次数多则表明算术强度高。
- 并行规模:一个 GPU 由多个流多处理器(SM)构成,而每个 SM 中有若干 CUDA 核心。每个 SM 是相对独立的,最多能驻留的线程个数一般是 2048。所以,一块 GPU 一共可以驻留几万到几十万个线程。如果一个核函数中定义的线程数目远小于这个数的话,就很难得到很高的加速比。
CUDA 的内存组织
CUDA 的内存组织简介
一般来说,现代计算机中的延迟低(速度高)的内存容量小,延迟高(速度低)的内存容量大。相对于 CPU 编程来说,CUDA 编程模型向程序员提供更多的控制权。因此,对 CUDA 编程来说,熟悉其内存的分级组织是非常重要的。
| 内存类型 | 物理位置 | 访问权限 | 可见范围 | 生命周期 |
|---|---|---|---|---|
| 全局内存 | 芯片外 | 可读可写 | 所有线程和主机端 | 由主机分配和释放 |
| 常量内存 | 芯片外 | 仅可读 | 所有线程和主机端 | 由主机分配和释放 |
| 纹理和表面内存 | 芯片外 | 一般仅可读 | 所有线程和主机端 | 由主机分配和释放 |
| 寄存器内存 | 芯片内 | 可读可写 | 单个线程 | 所在线程 |
| 局部内存 | 芯片外 | 可读可写 | 单个线程 | 所在线程 |
| 共享内存 | 芯片内 | 可读可写 | 单个线程块 | 所在线程块 |
CUDA 中的内存组织示意图如下:
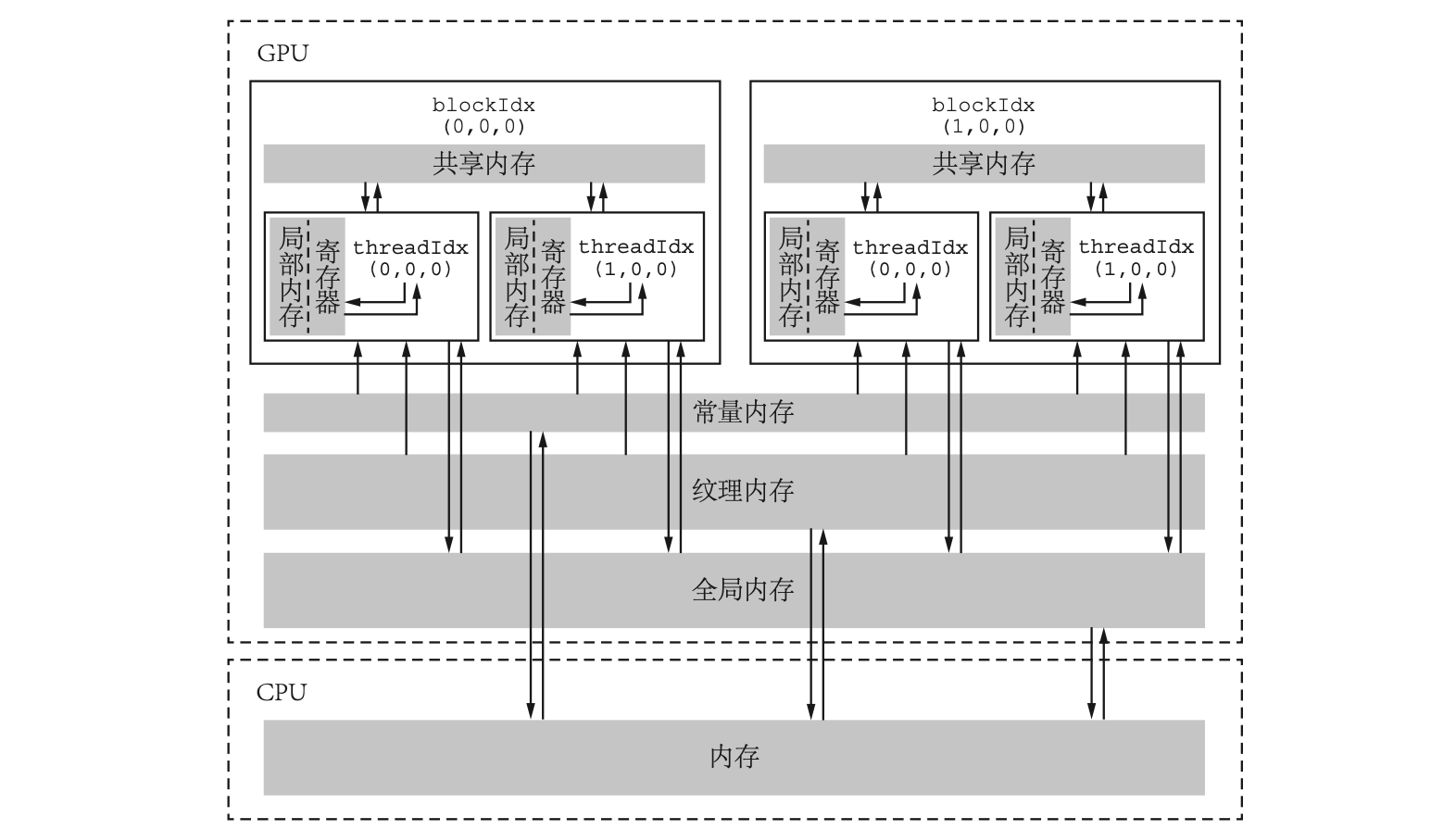
- 全局内存:核函数中的所有线程都能够访问其中的数据。容量约等于显存容量。
- 可以使用
cudaMalloc()为全局内存变量分配设备内存,用cudaMemcpy()将数据在主机和设备内存键复制。 - 也可使用
__device__ T y[N]来申请静态全局内存变量,修饰符__device__说明该变量是设备中的变量。
- 可以使用
- 常量内存:有常量缓存的全局内存,数量有限,一共仅有 64 KB,速度比全局内存快。使用
__constant__来修饰,核函数中的常量(如 const int N)其实就是常量内存。 - 纹理和表面内存:类似于常量内存,也是一种具有缓存的全局内存,有相同的可见范围和生命周期,但容量更大,而且使用方式和常量内存也不一样。将某些只读全局内存数据用
__ldg()函数通过只读数据缓存读取,既可达到使用纹理内存的加速效果。 - 寄存器:在核函数中定义的不加任何限定符的变量一般来说就存放于寄存器中,另外,内建变量 gridDim、blockDim、blockIdx、 threadIdx 及 warpSize 也都保持在特殊的寄存器中。
- 局部内存:局部内存和寄存器几乎一 样,核函数中定义的不加任何限定符的变量有可能在寄存器中,也有可能在局部内存中,一般数组就是在局部内存中。
- 共享内存:不同于寄存器的是,共享内存对整个线程块可见,其生命周期也与整个线程块一致。共享内存的主要作用是减少对全局内存的访问,或者改善对全局内存的访问模式。
- L1 和 L2 缓存:从费米架构开始,有了 SM 层次的 L1 缓存和设备层次的 L2 缓存。
SM 及其占有率
一个 GPU 是由多个流式多处理器 SM 构成的。一个 SM 通常包括寄存器、共享内存、L1 缓存、线程束调度器(Warp Scheduler)、执行核心(整数运算、单\双精度浮点数运算核心)。
因为一个 SM 中的各种计算资源是有限的,那么有些情况下一个 SM 中驻留的线程数目就有可能达不到理想的最大值。此时,我们说该 SM 的占有率小于 100%。一个 SM 中最多能拥有的线程块个数为 $N_b = 32$,最多能拥有的线程个数为 $N_t=2048$。
- 寄存器和共享内存使用量很少的情况。此时,SM 的占有率完全由执行配置中的线程块大小决定。在将线程块大小取 32 的整数倍的前提下,任何不小于 $N_t/N_b$ 而且能整除 $N_t$ 的线程块大小都能得到 100% 的占有率。
- 有限的寄存器个数对占有率的约束情况。如果我们希望在一个 SM 中驻留最多的线程(2048 个),若一个 SM 中有 64K 个寄存器,则核函数中的每个线程最多只能用 32 个寄存器。当每个线程所用寄存器个数大于 64 时,SM 的占有率将小于 50%。
- 有限的共享内存对占有率的约束情况。如果线程块大小为 128,那么每个 SM 要激活 16 个线程块才能有 2048 个线程,达到 100% 的占有率。此时,一个线程块最多能使用 3 KB 的共享内存。
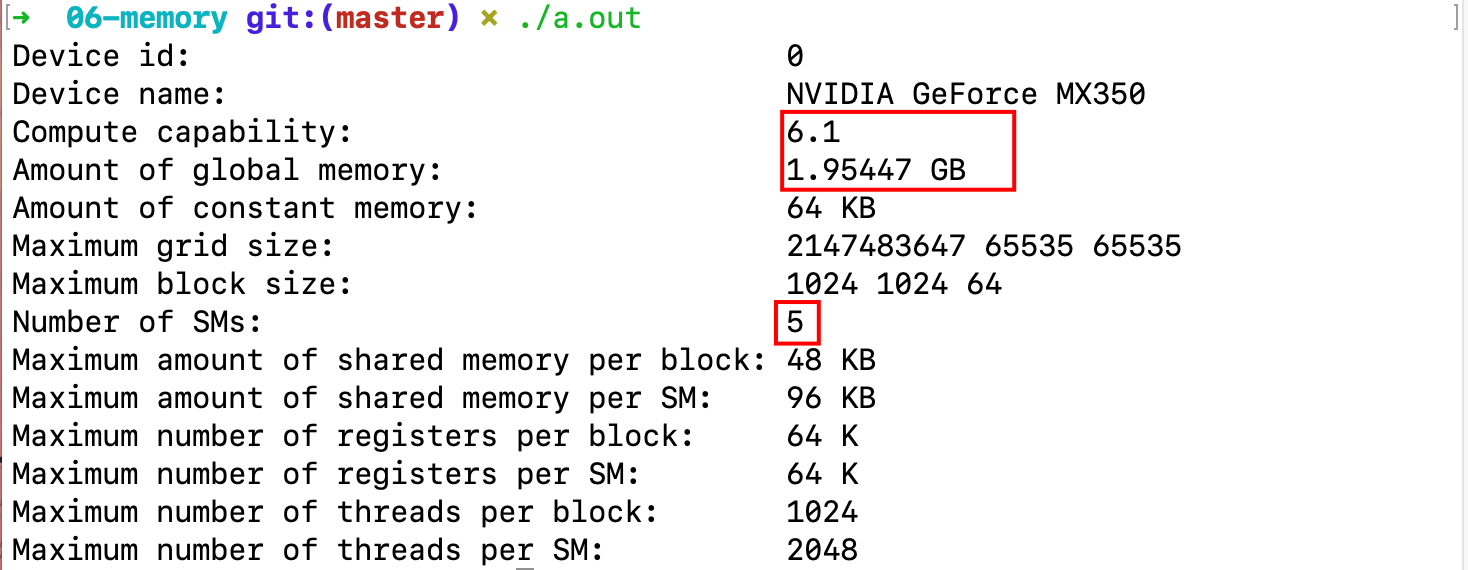
用 CUDA 运行时 API 函数查询设备
在 CUDA 工具箱中,有一个名为 deviceQuery.cu 的程序,可以输出相关信息。
全局内存的合理使用
全局内存的合并与非合并访问
对全局内存的访问将触发内存事务(memory transaction),也就是数据传输(data transfer)。关于全局内存的访问模式,有合并(coalesced)与非合并(uncoalesced)之分。合并 访问指的是一个线程束对全局内存的一次访问请求(读或者写)导致最少数量的数据传输, 否则称访问是非合并的。
定量地说,可以定义一个合并度(degree of coalescing),它等于线程束请求的字节数除以由该请求导致的所有数据传输处理的字节数。如果所有数据传输中处理的数据都是线程束所需要的,那么合并度就是 100%,即对应合并访问。
矩阵转置
下面的第一个核函数实现的是矩阵复制、第一个版本的转置函数对矩阵 B 是非合并写访问,对 A 是合并读访问;第二个版本的转置函数对矩阵 B 是合并写访问,对 A 是非合并读访问;第三个版本的转置函数对矩阵 B 是合并写访问,对 A 是非合并读访问但是使用了缓存来优化。
// 线程块大小为 TILE_DIM * TILE_DIM,real 为 float 或 double |
执行结果如下:
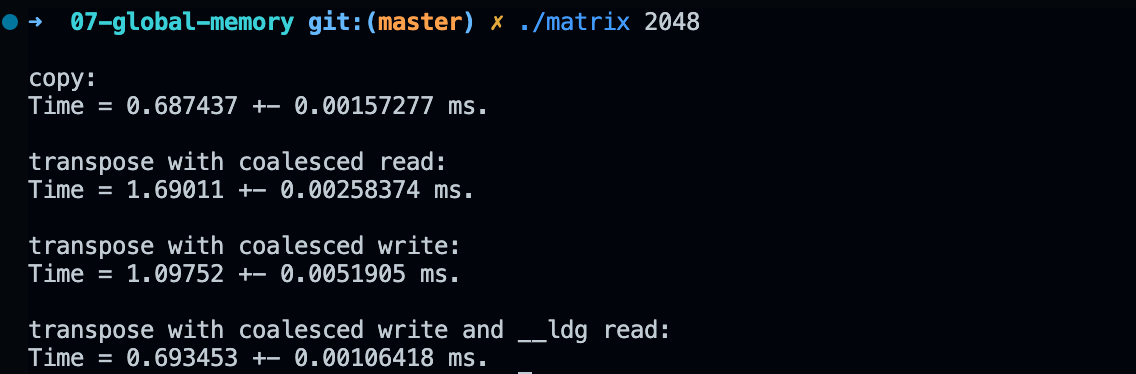
因此,我们可以认为,在合并写和合并读之间,应该优先选择合并写,可以获得更快的执行时间,同时利用缓存可以减轻非合并读带来的性能损失,达到和合并读(copy)基本一致的效率。
共享内存的合理使用
共享内存是一种可被程序员直接操控的缓存,主要作用有两个:一个是减少核函数中对全局内存的访问次数,实现高效的线程块内部的通信,另一个是提高全局内存访问的合并度。
数组规约计算
考虑一个有 N 个元素的数组 x,假如我们需要计算该数组中所有元素的和,这就是数组规约计算。考虑 C 语言版本,将数组元素初始化为 1.23,数组长度为 $10^8$,最后结果不是正确的,这是因为,在累加计算中出现了所谓的“大数吃小数”的现象。单精度浮点数只有 6、7 位精确的有效数字。
而 CUDA 版本的数组规约函数的思路如下,不妨设线程块大小为 128,即有 $10^8 / 128$ 个线程块,我们将每个线程块中的元素规约为一个值,则数组长度缩减了 128 倍。再对剩下的的长度为 $10^8 / 128$ 的数组进行普通规约。对于块内规约,第一步将后 64 个元素累加到前 64 个元素上,进行一次同步。然后将前 64 个元素中的后 32 个元素累加到前 32 个元素上,依次类推,需要执行 log128 次。
void __global__ reduce_global(real *d_x, real *d_y) { |
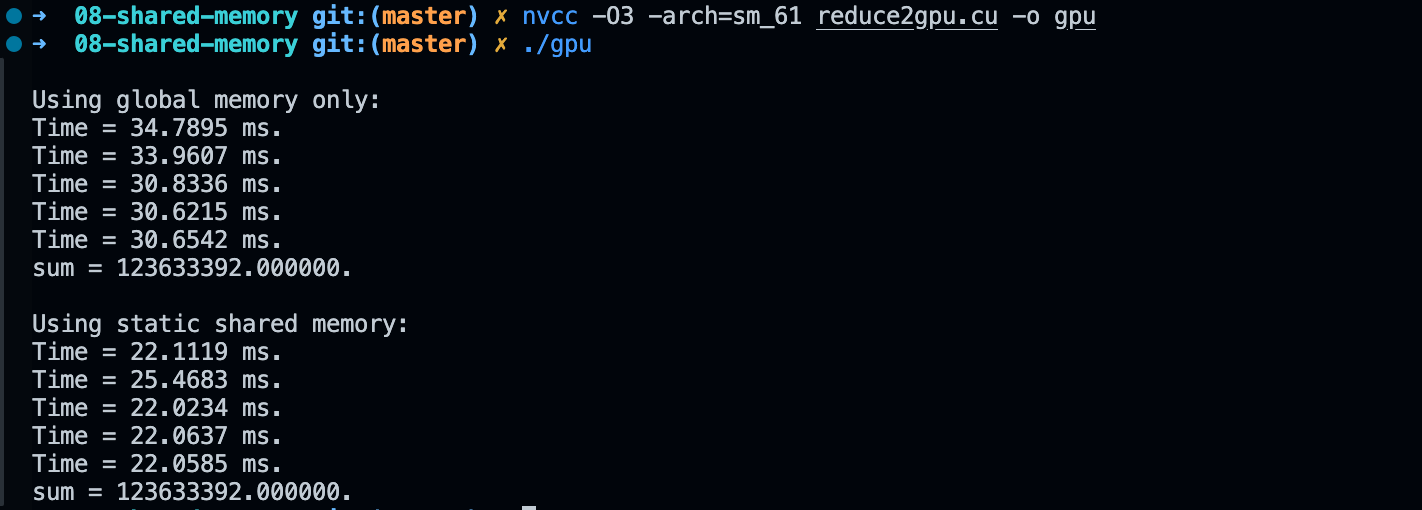
在上一个版本的核函数中,对全局内存的访问是很频繁的。全局内存的访问速度是所有内存中最低的,应该尽量减少对它的使用。首先,通过 __shared__ real s_y[128] 定义一个共享内存数组变量,然后将全局内存中的数据复制到共享内存中。在上一个版本中,对全局内存的读取次数是 128+64+32+…+2=255 次,写入次数是 64+32+…+1=127 次,在共享内存版本中,对全局内存的读取次数是 128 次,写入次数是 1 次。代码如下:
void __global__ reduce_shared(real *d_x, real *d_y) { |
执行效率对比如下:
bank 冲突
为了获得高的内存带宽,共享内存在物理上被分为 32 个同样宽度的、能被同时访问的内存 bank。对于 bank 宽度为 4 字节的架构,共享内存数组是按如下方式线性地映射到内存 bank 的: 共享内存数组中连续的 128 字节的内容分摊到 32 个 bank 的某一层中,每个 bank 负责 4 字节的内容。也就是说,每个 bank 分摊 32 个在地址上相差 128 字节的数据,如下所示。

在执行时,如果对共享矩阵的列进行遍历,且相邻线程访问的都是同一个 bank,就会发生 bank 冲突。最坏的情况是线程束内的 32 个线程同时访问同一个 bank 中 32 个不同层的地址,这将导致 32 路 bank 冲突。而与此对应的是,只要同一线程束内的多个线程不同时访问同一个 bank 中不同层的数据,该线程束对共享内存的访问就只需要一次内存事务。没有 bank 冲突的访问如下所示。

通常可以用改变共享内存数组大小的方式来消除或减轻共享内存的 bank 冲突。例如,将核函数中的共享内存定义修改为如下:
int TILE_DIM = 32; |
这样,S[0][0] 和 S[0][32] 位于 $𝑏𝑎𝑛𝑘_0$ 中,而 S[1][0] 位于 $𝑏𝑎𝑛𝑘_1$ 中,S[2][0] 位于 $𝑏𝑎𝑛𝑘_2$ 中,依此类推。这样,线程束内的 32 个线程将刚好访问 32 个 bank 中的 32 个数据,从而消除了 bank 冲突。
矩阵乘法
使用共享内存版的矩阵乘法,代码如下。考虑 $𝐴_{𝑚𝑛} = 𝐵_{𝑚𝑘} ∗ 𝐶_{𝑘𝑛}$,我们设置块大小为 32 × 32,在处理 $𝐶_{𝑠𝑢𝑏}$ 线程块时,首先将 s_a_1 和 s_b_1 块读入到共享内存,将图中使用蓝色线条标注的两个向量的点乘值累加到 $𝐶_{𝑖𝑗}$ 上。此时还不是最终结果,重复上面提到的运算,将 s_a_2 和 s_b_2 块读入到共享内存,然后将图中使红色线条标注的两个向量的点乘值累加到 $𝐶_{𝑖𝑗}$ 上,以此类推,就可以得到最终结果。
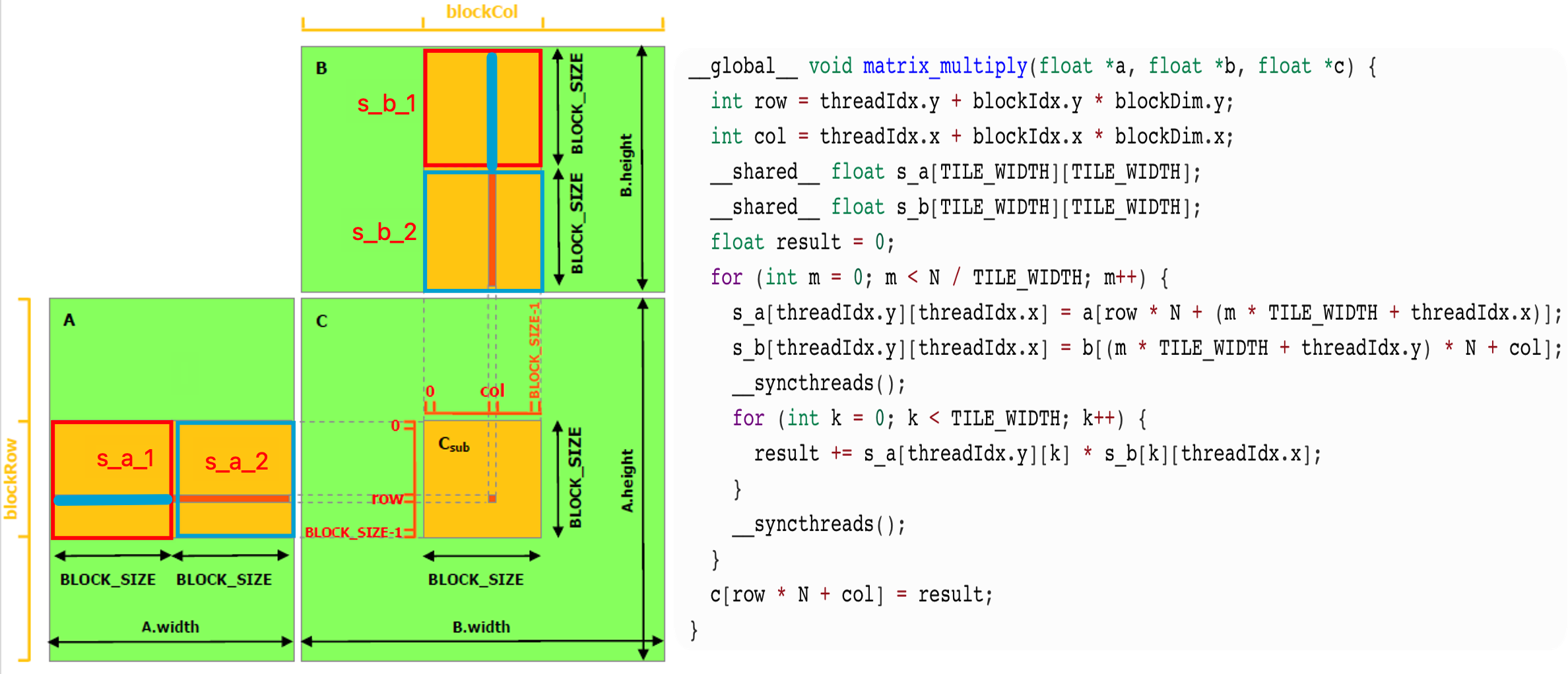
执行效率如下,矩阵的大小为 1024 × 1024:

原子函数的合理使用
在之前,我们将一个较长的数组在 GPU 中初步进行了规约,然后形成了一个较短的数组,再在主机中进行规约。现在,我们将完全在 GPU 中进行归约。有两种方法能够在 GPU 中得到最终结果,一是用另一个核函数将较短的数组进一步归约,一直递归得到最终的结果;二是在先前的核函数的末尾利用原子函数进行归约,直接得到最终结果。
void __global__ reduce_shared(real *d_x, real *d_y) { |
CUDA 流
CUDA 流是一个执行序列,其中 CUDA 操作(如内核执行,数据传输)按照它们被调用的顺序进行排队和执行。利用多个 CUDA 流可以实现操作的并发执行,这可以为显著提高总体执行速度提供可能。
在默认流中重叠主机和设备计算
同一个 CUDA 流中的所有 CUDA 操作都是顺序执行的,但依然可以在默认流中重叠主机和设备的计算。尽管数据传输时同步的,主机发出 cudaMemcpy() 执行命令后,要等待该命令执行完成。但核函数的启动是异步的,主机发出命令执行核函数之后不会等待该命令执行完毕,而会立刻得到程序的控制权。因此,主机可以利用这段时间执行一部分计算任务。
在本文使用的硬件测试中,使用单精度浮点数进行操作。结果显示,在同等数据量情况下,设备端的矩阵加法函数执行速度约为主机端函数的六倍。因此,我 们对主机函数处理的数据量进行了调整,使其为设备函数处理的数据量的六分之 一,从而让设备端与主机端函数的执行时间接近。测试结果显示,若不重叠计算,主机与设备函数的执行时间之和为 14.2 ms,而重叠计算时,主机与设备函数的执行时间之和为 7.8 ms。这说明在主机和设备函数的计算负载相匹配时,将主机函数安排在设备函数之后执行可以实现主机和设备函数的并行运算效果。换句话说, 我们可以通过这种方式有效地遮蔽主机函数的执行时间,从而提高整体程序性能。
用非默认 CUDA 流重叠多个核函数的执行
虽然在一个默认流中就可以实现主机计算和设备计算的并行,但是要实现多个核函数之间的并行必须使用多个 CUDA 流。这是因为,同一个 CUDA 流中的 CUDA 操作在设备中是顺序执行的,故同一个 CUDA 流中的核函数也必须在设备中顺序执行。
可以创建多个 CUDA 流,将计算任务分配到多个 CUDA 流中,从而实现多个核函数之间的并行。测试使用不同数量的 CUDA 流的加速效果如下图所示。每 一个 CUDA 流对应一个核函数,每个核函数使用 N 个线程。这里将加速比定义为在同样的任务量下使用单个流所用时间与使用多个流所用时间之比。
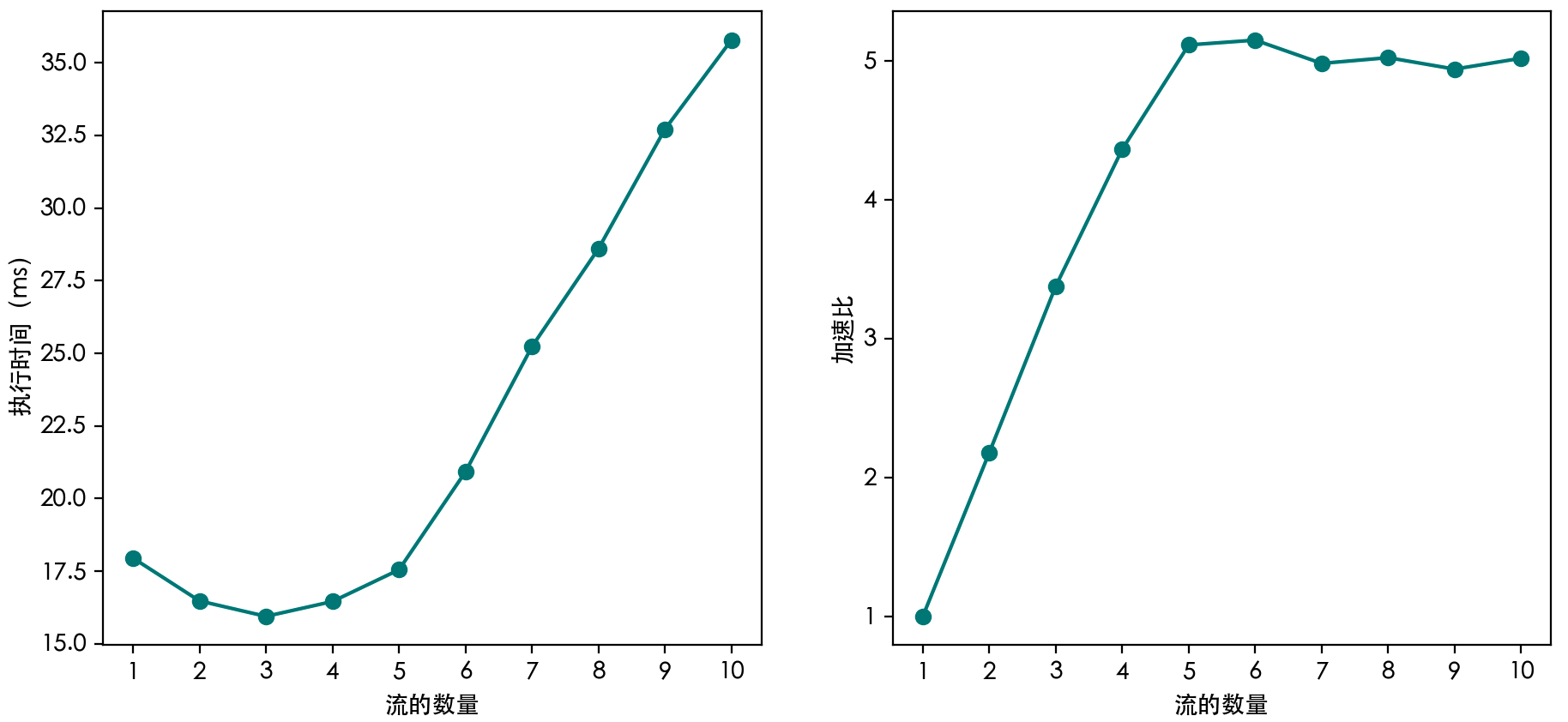
可以发现,在 CUDA 流数量为 1 到 5 时,执行时间基本不变,加速比呈线性增长。当 CUDA 流数量大于 5 之后,执行时间开始增加,加速比基本不变。这是因为,在本文使用 GPU 上,拥有 5 个 SM,可以并行执行这么多个核函数。理论上来说,使用非默认 CUDA 流重叠多个核函数的执行,最高可以达到接近 5 的计算性能加速比。
用非默认 CUDA 流重叠核函数的执行与数据传递
在编写 CUDA 程序时要尽量避免主机与设备之间的数据传输,但这种数据传输一般来说是无法完全避免的。在一段 CUDA 程序中,需要先从主机向设备传输一定的数据,将次操作记为 H2D,然后在 GPU 中使用所传输的数据做一些计算,将此 CUDA 操作简称为 KER,最后将数据从设备传输至主机,将此操作记为 D2H。
如果仅使用一个 CUDA 流 (如默认流),那么以上 3 个操作在设备中一定是顺序的:
Stream 0: H2D -> KER -> D2H |
如果简单地将以上 3 个 CUDA 操作放入 3 个不同的流,相比仅使用一个 CUDA 流 的情形依然不能得到加速,因为以上 3 个操作在逻辑上是有先后次序的。其执行流程如下:
Stream 1: H2D |
要利用多个流提升性能,就必须创造出在逻辑上可以并发执行的 CUDA 操作。一个方法是将以上 3 个 CUDA 操作都分成若干等份,然后在每个流中发布一个 CUDA 操作序列。例如,使用三个流时,我们将以上 3 个 CUDA 操作都分成三等份。在理想情况下,它们的执行流程可以如下:
Stream 1: H2D -> KER -> D2H |
这里的每个 CUDA 操作所处理的数据量只有使用一个 CUDA 流时的三分之一。和 CPU 指令的流水线执行很类似。随着流的数量的增加,在理想情况下能得到接近 3.0 的加速比。
要实现核函数执行与数据传输的并发,必须让这两个操作处于不同的非默认流,而且数据传输必须使用 cudaMemcpy() 函数的异步版本,即 cudaMemcpyAsync() 函数。异步传输由 GPU 中的 DMA 直接实现,不需要主机参与。在使用异步的数据传输函数时,需要将主机内存定义为不可分页内存,不可分页内存,在程序运行期间其物理地址将保持不变。不可分页内存可由 cudaMallocHost() 函数实现。
int M = N / NUM; |
分别测试了不同 CUDA 流数量下的执行耗时,并分析了 CUDA 流带来的加速比,结果如下所示。
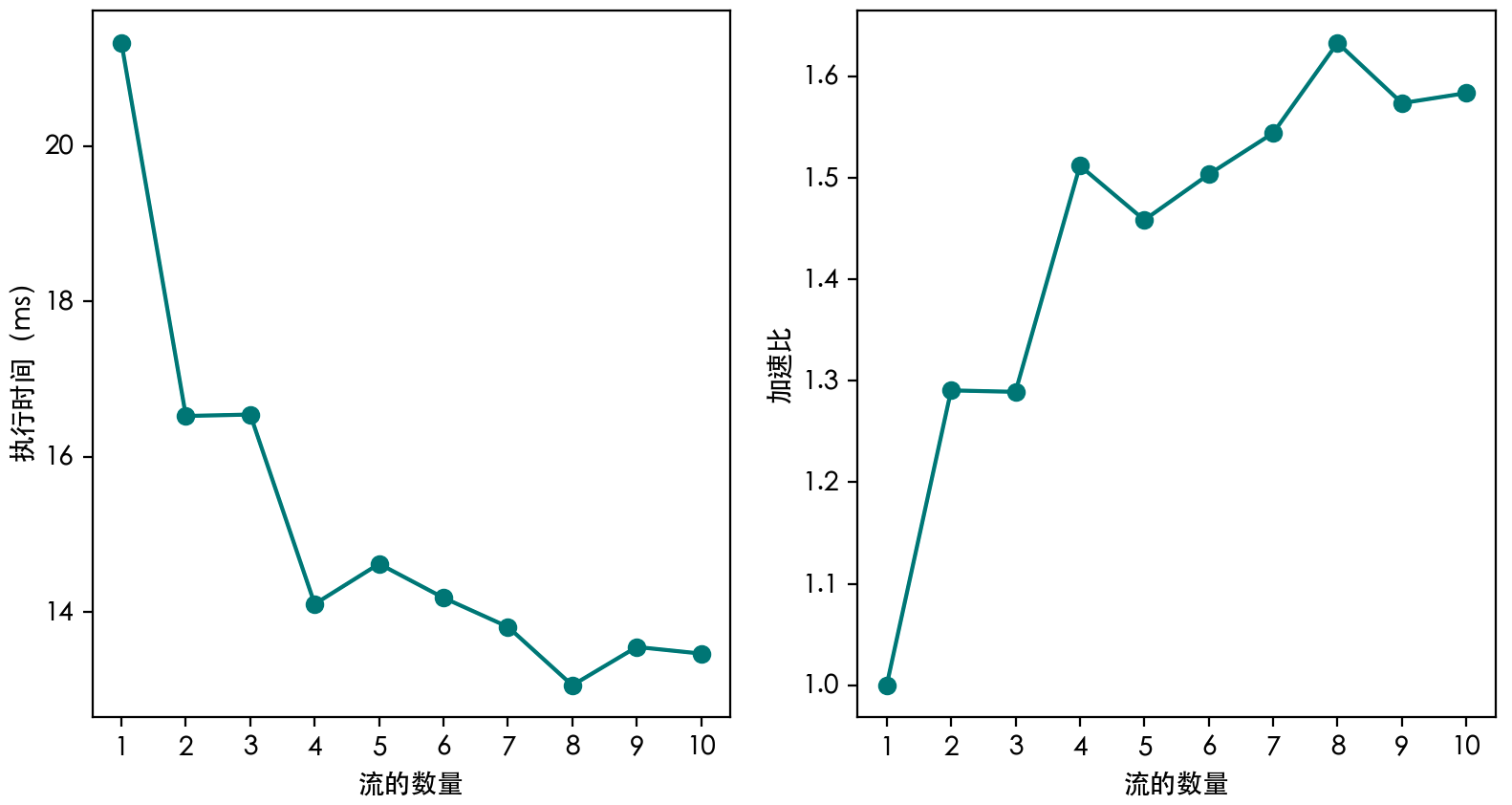
如果核函数执行、主机到设备的数据传输及设备到主机的数据传输这 3 个 CUDA 操作能完全并行地执行,那么理论上最大的加速比应该是 3。但在我们的测试中,使用 8 个流达到了约 1.6 倍的加速比。没有得到最高的加速比的原因主要有两个:第一,并行的三种 CUDA 操作执行时间并不完全一样。第二,每个流中的第一个 CUDA 操作都是从主机向设备传输数据,它们无法并发地执行。另外,我们注意到,当流的数量超过 8 时,加速比开始减小,这可能与由多个流带来的额外开销有关。
统一内存编程
在统一内存(unified memory)编程模型下,将不再需要手动地在主机与设备间传输数据。在统一内存之前,还有一种零复制内存(zero-copy memory)。它们都提供了一种统一的能被 CPU 和 GPU 都访问到的存储器,但零复制内存只是用主机内存作为存储介质,而统一内存则能将数据放在一个最合适的地方(可以是主机,也可以是设备)。
统一内存使CUDA编程更加简单。使用统一内存,将不再需要手动将数据在主机与设备之间传输,也不需要针对同一组数据定义两个指针,并分别分配主机和设备内存。 对于某个统一内存变量,可以直接从 GPU 或者 CPU 中进行访问。传输还是存在,只不过无需程序员指定。
底层的统一内存实现,可能会自动将一部分数据放置到离某个存储器更近的位置(如部分放置到某卡的显存中,部分放置到内存中),这种自动的就近数据存放,有可能提升性能。
允许 GPU 在使用了统一内存的情况下,进行超量分配。超出 GPU 内存额度的部分可能存放在主机上。
|
线程束基本函数与协作组
ToDo