内核基本数据结构
Task_struct(进程结构)
源代码:/linux/include/linux/sched.h 中 1000 行附近。
这个数据结构就是 PCB ,包含了进程的所有信息。这个结构体有大概 400 行代码,我们只需要了解一下我们需要的即可,主要包括以下内容:
struct task_struct { |
- state:表示进程状态(-1 就绪态,0 运行态,>0 停止态)
- stack:进程内核栈
- usage:有几个进程在使用此结构(这是一个原子变量)
- flags:标记,反映一个进程的状态信息,但不是运行状态。
- ptrace:关于实现断点调试,跟踪进程运行的系统调用
- pid,tgid:进程标识符和进程组标识符
- parent,children:父进程和子进程
结构体中剩下的一些成员还包括性能诊断工具、进程调度、时间与定时器、信号处理和文件系统信息等。
super_block(超级块)
源代码:/linux/include/linux/fs.h 中 1200 行附近。
超级块中包含的信息描述了文件系统的布局,每个文件系统都只有一个超级块。当启动或挂载其他文件系统时,它们的超级块也会被读入内存。
struct super_block { |
- s_list:是一个双向循环链表,把所有的 super_block 连接起来,这个 list 上边就是所有在 linux 上记录的文件系统。
- s_dev:包含该具体文件系统的块设备标识符。
- s_blocksize:文件系统中数据块大小,以字节为单位
- s_blocksize:上面的 size 大小占用位数
- s_maxbytes:允许的最大的文件大小
- s_flags:安装标识
- s_magic:区别于其他文件系统的标识
- s_count,s_active:对超级块的使用计数和引用计数
inode
源代码:/linux/include/linux/fs.h 中第 500 行附近。
每个文件都有一个 inode ,其主要功能就是给出文件数据块所在的位置,存放关于文件的一般信息。要打开一个文件,需要先找到它的 inode 。主要内容如下:
struct inode { |
- i_mode:文件的访问权限,如 rwxrwxrwx
- i_uid,i_gid:inode 拥有者和拥有者组 id
- i_flags:标志
- i_ino:inode 号,唯一确定一个文件
- i_size:文件大小
- i_blocks:文件使用块的数目
- i_count:引用计数
内存管理原理
页表
linux 从线性内存地址到物理内存地址采用的寻址方法是如图所示的多级页表寻址:
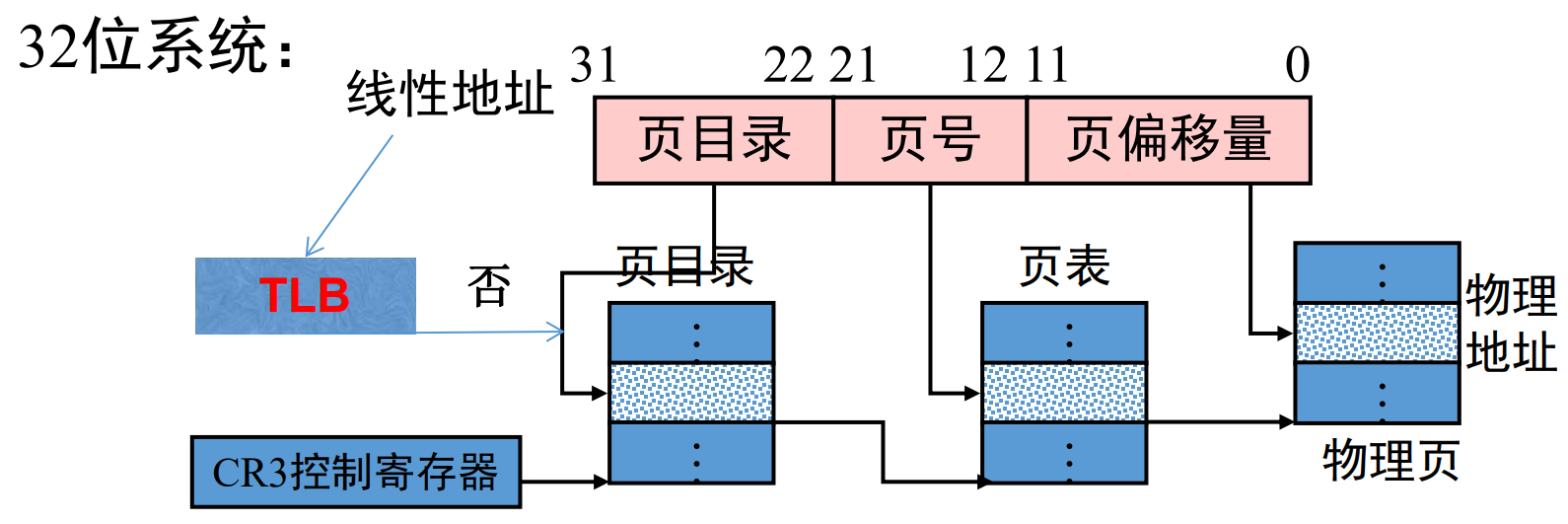
采用页表来寻址可以可以屏蔽物理内存的不连续性,虽然我们的程序零碎的分布在物理内存的各个位置,但是页表可以营造一种虚拟地址连续的假象。
采用多级页表,可以减小页表的大小,加快寻址速度。有映射的就建立起页表,没有的就不用,可以避免页表过大。
物理页面
接下来,我们看一下物理页,使用 page 来表示,每个物理页由一个 page 唯一决定。我们设置一个 mem_map[] 数组管理内存页面 page 。page 这个结构体定义在:
/include/linux/mm_types.h 中第 50 行附近。
主要的内容如下:
struct page { |
- flag:用来存放页的状态,是否脏页,是否锁定,是否换出。
- mapping:指向与该页相关的 address_space 对象。
- mapcount:被页表映射的次数,也就是说该 page 同时被多少个进程共享。
- refcount:引用计数,表示内核中引用该 page 的次数。当该值为 0 时, 表示没有引用该 page 的位置。
- active:经常被访问的处于活跃状态的页面。
- next:指向 slab 链表的指针。
因为每一个物理页都有一个 page 结构体,所以需要尽可能的节省空间,因此,page 结构体中使用了很多 union 联合体。
Buddy 算法
源代码:/mm/page_alloc.c 中
代码比较复杂,总体思路是把所有的空闲页框分组为 n 个块链表,每个块链表分别包含大小为 1,2,4,8,16,32,64… 个连续页框的页框块。每个页框块的第一个页框的物理地址是该块大小的整数倍。
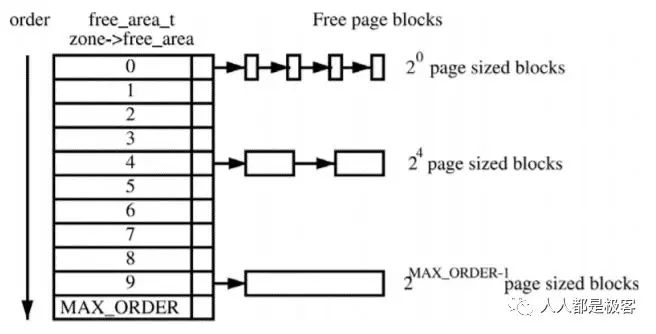
分配算法:比如我们我们需要分配一个 640MB (512 + 128)的内存大小,会查找大小为 1024MB 的页框块,分配 640MB 后还剩余 384(256 + 128)MB,我们把剩下的拆分后分配给大小为 256MB 和 128MB 的页框块链表。这样,可以避免内存的浪费。
回收算法:当我们上面的内存使用完成后,会被释放,同时检查被分配给其他页框块链表的内存空间,如果都没有被使用,则会合并内存,重新得到一个大小为 1024MB 的页框块。
Slab 算法
buddy 算法解决了大内存空间的分配问题,而 slab 算法就是用来解决小内存空间的分配问题。
slab分配器分配内存以字节为单位,基于伙伴分配器的大内存进一步细分成小内存分配。换句话说,slab 分配器仍然从 Buddy 分配器中申请内存,之后自己对申请来的内存细分管理。slab 分配器的第二个任务是维护常用对象的缓存,因为很多小内存对象频繁的构造和销毁,如果直接从缓存器中分配可以减少构造时的初始化时间,销毁后存储在缓存器中,供下次构造使用。slab 分配器的最后一项任务是提高 CPU 硬件缓存的利用率。 如果将对象包装到 slab 中后仍有剩余空间,则将剩余空间用于为 slab 着色。 slab 着色是一种尝试使不同 slab 中的对象使用 CPU 硬件缓存中不同行的方案。
使用如下三个函数来分配和回收内存:
- 分配内存:void * kmalloc (size_t size,gfp_t flags);
- 重新分配内存:void *krealloc(const void *p, size_t new_size, gfp_t flags);
- 释放内存:void kfree ( const void * objp);
struct slab { |
- 每个内存缓存对应一个kmem_cache实例。
- 每个内存节点对应一个kmem_cache_node实例。
- kmem_cache实例的成员cpu_slab指向arrary_cache实例。每个处理器对应一个arrary_cache实例,称为数组缓存,用来缓存刚刚释放的对象,分配时首先从当前处理器的数据缓存分配,避免每次都要从slab分配,减少链表操作的锁操作,提高分配速度。
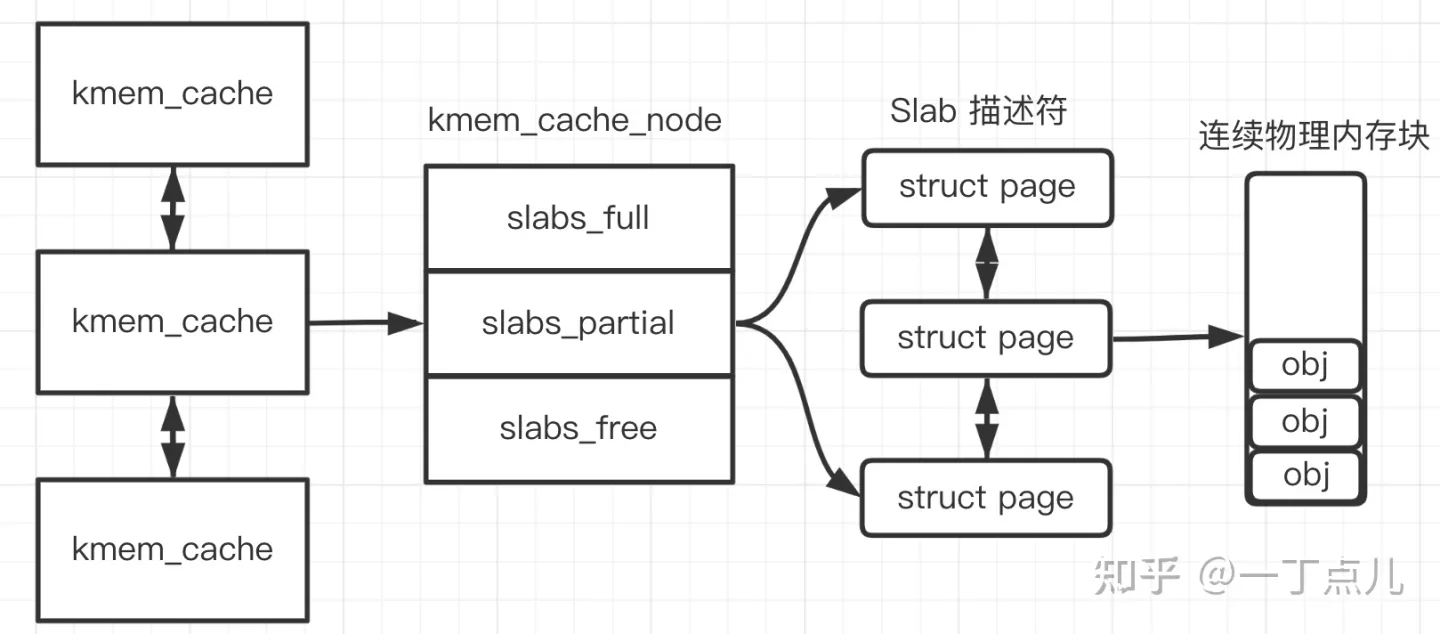
用 struct kmem_cache 结构描述的一段内存就称作一个 slab 缓存池。一个slab缓存池就像是一箱牛奶,一箱牛奶中有很多瓶牛奶,每瓶牛奶就是一个 slab 。在初始时,所有牛奶都是新的,都存在 slabs_free 链表中。分配内存的时候,就相当于从牛奶箱中拿一瓶牛奶,若把一瓶牛奶喝完,该牛奶就会被加入到 slabs_full 中不能再分配;若只喝了一半就放回到 slabs_partial 中。牛奶可能会喝完(不考虑 slab 内存 free 的情况,因为自己不能生产牛奶(捂脸)),当箱子空的时候,你就需要去超市再买一箱回来。超市就相当于buddy 分配器。
小结
linux 内核的基本数据结构包括进程控制的核心数据结构 task_struct 和文件系统的核心数据结构 super_boclk 以及文件的唯一标识 inode 等;内存管理包括虚拟地址到物理地址的映射—-页表和物理内存的两种内存管理方法 slab 和 buddy。这两种方法分别解决了小内存和大内存空间的分配问题。