1 虚拟化技术
KVM(Kernel-based Virtual Machine)是 Linux 内核中的原生虚拟化解决方案,借助硬件辅助虚拟化技术,在一台物理服务器上运行多个独立的虚拟机(VM),每台虚拟机可运行不同的操作系统(如 Windows、Ubuntu 等)。KVM 依赖 硬件虚拟化支持、Hypervisor 架构和 QEMU 用户态模拟器,广泛应用于云计算平台(如 OpenStack、Proxmox)及生产环境中的虚拟化部署。
1.1 硬件辅助虚拟化
现代 x86 架构 CPU(如 Intel VT-x、AMD-V)内置了虚拟化指令集扩展,允许虚拟机的指令在物理 CPU 上原生执行,从而提升性能并降低虚拟化的实现复杂度。
CPU 虚拟化模式:CPU 支持两种运行模式:
- Root Mode(VMX Root):宿主机(Hypervisor)运行的模式;
- Non-Root Mode(VMX Non-Root):虚拟机运行的模式。
当虚拟机需要执行特权操作(如访问 I/O 设备、CR3 切换等),会触发 VM-exit,退出 Non-Root Mode,由 KVM 接管处理。
[!NOTE] 硬件虚拟化极大减少了二进制翻译等传统软件模拟技术的开销,使得虚拟机运行更接近原生性能。
1.2 Hypervisor 架构(KVM)
Hypervisor 是一种软件、固件或硬件层,用来在物理硬件和虚拟机(VM)之间提供隔离与资源调度。它的主要作用是模拟一个完整的计算机系统(CPU、内存、磁盘、网络等);管理多个虚拟机对底层物理资源的访问;保证虚拟机之间的安全隔离和资源公平使用。
| 类型 | 说明 | 示例 |
|---|---|---|
| Type-1 | 裸金属型,直接运行在硬件上,性能高、安全性强 | KVM、Xen、ESXi |
| Type-2 | 宿主型,运行在操作系统之上,适合桌面环境 | VirtualBox、VMware Workstation |
KVM 就是一个 Type-1 类型的 Hypervisor:
- 虽然 KVM 运行在 Linux 内核中,但加载 kvm.ko 模块后,Linux 内核本身就充当了 Hypervisor 的角色,因此被归类为 Type-1。
- 每个虚拟机以一个普通的 Linux 进程存在,便于调度、监控、资源隔离。
1.3 QEMU:用户态虚拟设备模拟器
KVM 本身只提供 CPU 和内存的虚拟化能力,而不包含虚拟设备(磁盘、网卡、显卡等)模拟能力。QEMU(Quick Emulator)是与 KVM 配套使用的用户空间模拟器,补全虚拟设备层。
- QEMU 提供完整的虚拟硬件模型(磁盘、网卡、显卡、USB 等)
- QEMU 利用 /dev/kvm 接口,将 CPU 虚拟化任务委托给 KVM,自己处理设备模拟
- QEMU 默认效率不高,有一些设备加速机制:
- 纯软件模拟:性能低(例如 qemu-system-x86_64 不加任何加速参数时)
- KVM 加速:借助 -enable-kvm 参数启用 KVM 模块,提高执行效率
- Virtio 半虚拟化设备:提高磁盘和网络 I/O 性能(绕过传统设备模拟,直接和宿主机通信)
虚拟机启动:
QEMU 启动并创建虚拟硬件环境
↳ KVM 接管 CPU 和内存虚拟化
↳ 虚拟机进入 VMX Non-Root 模式执行
↳ 触发 I/O 或中断时 VM-exit 回到 KVM
↳ KVM 通知 QEMU 模拟设备行为
1.4 虚拟化与容器化
虚拟化与容器化都能实现资源隔离与多租户,但其实现原理、性能表现和适用场景不同:
| 维度 | 虚拟化(KVM) | 容器化(Docker) |
|---|---|---|
| 架构 | Hypervisor + 独立 OS | 共享宿主机内核 |
| 启动时间 | 慢(10-60 秒) | 快(毫秒级) |
| 镜像大小 | 大(GB 级别) | 小(MB 级别) |
| 性能 | 较高,但有 I/O 虚拟化开销 | 接近原生 |
| 隔离性 | 强(内核级) | 中等(用户空间) |
| 安全性 | 高(独立内核,防越权) | 适中(共享内核,需额外防护) |
| 资源调度 | 固定分配(vCPU、内存) | 动态分配(cGroup 限制) |
| 场景 | 多 OS、多租户、高安全需求 | 微服务、CI/CD、快速部署 |
2 Linux 容器基础
2.1 容器(Container)
容器是一种轻量级的虚拟化技术,它允许在同一操作系统内核上运行多个相互隔离的用户空间实例。与传统的虚拟机(VM)不同,容器不包含完整的操作系统,而是共享宿主机的内核。这种共享机制带来了以下优势:
- 启动速度快:容器省略了操作系统的引导过程,秒级启动。
- 占用资源少:共享内核,省去了冗余系统资源开销。
- 迁移与交付便捷:容器镜像打包了应用及其依赖,使得跨环境部署更容易实现 " 构建一次,到处运行 “。
容器通常包括:应用程序代码、运行时、依赖库、配置文件等。用户通过镜像构建容器,运行容器时基于镜像启动一个进程,并运行在隔离环境中。
2.2 Namespace(命名空间)
Namespace 是 Linux 提供的一种进程级资源隔离机制,用于将系统的全局资源划分为多个隔离单元。每类命名空间隔离特定类型的资源。主要包括:
- PID Namespace:进程 ID 隔离,容器内的进程拥有独立 PID,彼此不可见。
- Network Namespace:网络隔离,容器可拥有独立的网络设备、IP 地址、路由表等。
- Mount Namespace:文件系统挂载隔离,容器有独立的挂载点视图。
- UTS Namespace:主机名和域名隔离,容器可设置自己的 hostname。
- User Namespace:用户和组 ID 隔离,容器内的 root 用户可映射为宿主上的非特权用户。
- IPC Namespace:进程间通信隔离,容器内的消息队列、信号量等资源相互隔离。
sudo unshare --fork --pid --mount-proc bash
这条命令使用了 Linux 的 unshare 工具,它的作用是创建一个新的命名空间,并将后续的进程放入这个独立的命名空间中。让我们逐个分析选项:
--fork:fork 出新进程应用命名空间隔离效果,避免影响当前 shell;--pid:新建 PID 命名空间,进程从 PID 1 开始编号;--mount-proc:在新命名空间中重新挂载/proc而不是共享宿主机,防止暴露宿主机进程信息。
进入后执行 ps 命令,仅能看到当前命名空间下的进程(如 bash 和 ps 本身)。
如需隔离网络,可加 --net,进入命名空间后使用 ip link 可看到只有 loopback 接口。
2.3 Cgroups(控制组)
Cgroups(Control Groups)用于限制、记录和隔离进程组的资源使用。支持控制的资源包括:
- CPU 时间(cpu、cpuacct)
- 内存使用量(memory)
- 磁盘 I/O(blkio)
- 网络带宽(net_cls)
Cgroups 构建为层次结构,每个 Cgroup 作为节点存在于 /sys/fs/cgroup 的子系统中。每个子系统在该目录下是一个独立的挂载点,如 /sys/fs/cgroup/memory、/sys/fs/cgroup/cpu 等;每个 Cgroup 实际上是这个目录中的一个子目录,例如 /sys/fs/cgroup/memory/my-process/。
首先,需要安装 cgroup-tools 包,因为它提供了操作 Cgroups 的命令行工具(cgcreate、cgexec 等),在基于 Debian 的系统(如 Ubuntu)上,可以运行 sudo apt-get install cgroup-tools。然后使用 cgcreate 命令可以创建一个新的 Cgroup。例如:
sudo cgcreate -g memory:my-process
- -g:指定子系统与路径格式为
<subsystem>:<path>; memory:/my-process:在 memory 子系统中创建名为 my-process 的控制组。
执行这条命令后,系统会在 /sys/fs/cgroup/memory 目录下创建一个名为 my-process 的子目录。这个目录包含多个文件,用于设置和管理该 Cgroup 的资源限制,例如:
memory.limit_in_bytes:设置该 Cgroup 中进程可使用的最大内存量,以字节为单位。memory.kmem.limit_in_bytes:限制内核内存使用。
要为 my-process Cgroup 设置一个 50MB 的内存限制,可以运行:
sudo echo 50000000 > /sys/fs/cgroup/memory/my-process/memory.limit_in_bytes
使用 cgexec 启动一个进程,该进程将受 my-process Cgroup 管控:
sudo cgexec -g memory:my-process bash
通过 cgclassify 命令或手动将已有进程加入某个 Cgroup:
# 获取进程 PID
pidof your_app
# 将进程加入 cgroup
echo <PID> | sudo tee /sys/fs/cgroup/memory/my-process/tasks
2.4 Cgroups with Namespace
Namespace 和 Cgroups 是实现容器的两大支柱,它们相辅相成:
- 隔离(Namespace):Namespace 负责将容器的运行环境与宿主系统和其他容器隔离开来。例如,通过 PID Namespace,容器内的进程看不到宿主系统的其他进程;通过 Network Namespace,容器拥有独立的网络栈。
- 资源控制(Cgroup):Cgroup 负责限制容器使用的资源,避免某个容器耗尽系统资源。例如,一个容器可能被限制在 2 个 CPU 核心和 512MB 内存内运行。
- 协同作用:Namespace 提供 " 边界 “,让容器内的进程感觉自己独占系统;Cgroup 提供 " 天花板 “,限制这个边界内的资源使用。二者结合,实现了既独立又可控的运行环境。
可以使用 cgroups 与 namespaces 来创建一个独立的进程,并限制其可使用的资源。
sudo cgexec -g cpu,memory:my-process unshare -uinpUrf --mount-proc sh -c "/bin/hostname my-process && chroot mktemp -d /bin/sh"
cgexec -g cpu,memory:my-process- 使用
cgexec在指定的 Cgroup 中运行后续命令。 -g cpu,memory:my-process:将进程放入名为my-process的 Cgroup,同时限制其 CPU 和内存资源。前提是你已通过cgcreate -g cpu,memory:my-process创建了这个 Cgroup,并设置了限制(如memory.limit_in_bytes)。
- 使用
unshare- 创建新的命名空间,实现进程环境的隔离。
-u(UTS Namespace):隔离主机名和域名。-i(IPC Namespace):隔离进程间通信资源。-n(Network Namespace):隔离网络资源,如网络接口和 IP。-p(PID Namespace):隔离进程 ID,进程在新命名空间中从 PID 1 开始。-U(User Namespace):隔离用户和组 ID,支持权限隔离。-r:将当前用户映射为新命名空间中的 root 用户(需配合-U)。-f(fork):在新命名空间中 fork 一个子进程,避免影响当前 shell。--mount-proc:在新 PID Namespace 中重新挂载/proc,确保进程视图隔离。
sh -c "/bin/hostname my-process && chroot mktemp -d /bin/sh"- 在新环境中运行一个 shell,并执行指定的命令。
/bin/hostname my-process:设置新命名空间的主机名为my-process(依赖 UTS Namespace)。chroot mktemp -d /bin/sh:mktemp -d:创建一个临时目录。chroot:将进程的根文件系统切换到这个临时目录。/bin/sh:在新根目录下启动一个 shell。
这条命令手动实现了一个简易容器:Namespace 提供隔离,Cgroup 提供资源控制,chroot 提供文件系统隔离。这正是 Docker 等容器技术的基础原理,只不过 Docker 封装得更高级(镜像管理、网络配置等)。
2.5 OverlayFS(联合文件系统)
OverlayFS 是 Linux 内核支持的一种轻量级 联合挂载(Union Mount)文件系统,广泛应用于 Docker 等容器技术中。它通过将多个目录「合并挂载」为一个统一视图,提供了分层管理、只读共享与写时复制(Copy-on-Write)等机制。其结构包括:
- LowerDir:只读层,通常由一个或多个 Docker 镜像层组成;
- UpperDir:可写层,记录容器运行时产生的新增/修改/删除;
- WorkDir:OverlayFS 操作所需的中间目录,必须为空目录;
- MergedDir:最终挂载点,用户和进程实际访问的统一文件视图。
文件的操作规则:
- 读操作:从 UpperDir 查找,找不到则从 LowerDir 查找。
- 写操作:写时复制(Copy-on-Write),将 LowerDir 文件复制到 UpperDir 再修改。
- 删除操作:在 UpperDir 中创建白出文件(whiteout),遮蔽 LowerDir 中的同名文件。
Docker 镜像由多层只读镜像层组成,每层可看作一个 LowerDir。每个 Dockerfile 指令(如 FROM、RUN)都会生成一个新的镜像层。多个容器可共享相同的镜像层,节省存储空间。
当运行容器时,Docker 创建一个新的 UpperDir(容器层)与镜像层(LowerDir)组合成一个 OverlayFS。所有的写操作(新增/修改/删除)都只会落到 UpperDir,不会影响原始镜像。容器停止后,UpperDir 可以删除而不影响镜像本体,支持快速回滚与重建。
3 容器运行时
容器的本质是 Linux 提供的资源隔离机制(如 Namespace 与 Cgroups)构建出的轻量级运行环境,用于运行一个进程及其依赖。但仅靠底层命令行工具来手动创建容器,存在以下挑战:
- 操作复杂:需手动配置多个子系统:unshare 创建命名空间、mount 挂载文件系统、cgroup 限制资源、chroot 修改根目录;
- 管理困难:当容器数量较多时,手动方式难以统一管理;无法查看容器状态、运行进程、使用资源等元数据。
- 重复劳动:已构建的镜像存在于远程仓库(如 Docker Hub),但无法便捷拉取和运行;容器创建过程无法复用,效率低下。
为简化容器创建与管理流程,人们设计了 容器运行时(Container Runtime) —— 一个统一的容器生命周期管理工具。Container Runtime 是管理容器生命周期的工具,涵盖创建、删除、打包和共享容器,可以分为两类:
- 低级容器运行时:启动隔离的进程(通过 namespace、cgroup 等),完成真正的容器运行;
- 高级容器运行时:负责整个容器生命周期管理,支持镜像的拉取、解包与缓存。
[!NOTE]
- Container Image 是一个只读的、轻量级的文件包,包含了运行容器所需的所有内容:应用程序代码、运行时环境、系统库、配置文件等。它就像一个快照,捕捉了容器运行时的完整状态。在 Docker 中,你可以用 Dockerfile 定义镜像内容,然后通过 docker build 打包成镜像。
- Container Registry 是一个存储和管理容器镜像的仓库,通常运行在云端或本地服务器上。它类似于代码的 GitHub,但专为容器镜像设计。
3.1 低级容器运行时
低级容器运行时是容器技术栈中最贴近操作系统内核的部分,负责创建、运行、监控、销毁容器进程。它不具备镜像管理、网络配置、日志收集等高级功能,主要职责是启动一个隔离的、资源受限的进程。低级容器运行时通常被高级运行时(如 containerd、Docker)调用,它会接收配置(如 config.json),调用内核特性来完成容器的构建与清理。
- 资源限制(Cgroups):低级容器运行时通过 Cgroup 控制组为容器设置资源限制,如 CPU、内存等。它会创建对应的 Cgroup 层级,并将容器主进程加入其中,确保进程在受控资源范围内运行。
- 进程隔离(Namespaces):为了实现容器进程的环境隔离,运行时使用 clone() 或 unshare() 创建多个命名空间,如 PID、网络、IPC、UTS、挂载、用户等,使容器内的视角与宿主和其他容器完全隔离。
- 文件系统隔离(chroot / pivot_root):运行时会为容器设置独立的根文件系统,通常通过解包镜像构建 rootfs。然后使用 chroot() 或 pivot_root() 切换根目录,并挂载必要的目录(如 /proc、/dev),实现文件系统隔离。
- 容器初始化与进程启动:在隔离环境就绪后,运行时会执行用户指定的程序(如 bash),并设置环境变量、工作目录等。该进程成为容器的主进程,运行时负责跟踪其生命周期。
- 容器清理:当容器进程结束后,运行时会自动清理相关资源,包括卸载挂载点、释放 Cgroup、销毁命名空间,并可删除容器的 rootfs,从而保证资源不泄露。
runc 是最常见的低级容器运行时,由 Open Container Initiative(OCI)标准化,广泛应用于 Docker 等高级运行时底层。它的作用是根据配置文件创建并运行容器。下面启动了一个名为 runc-container 的容器。
runc run runc-container
3.2 高级容器运行时
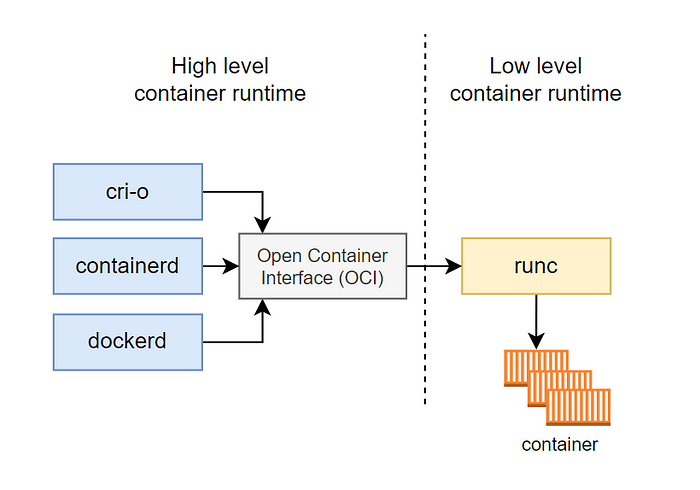
containerd 是 CNCF 托管的一个高级容器运行时,负责管理容器的整个生命周期,包括镜像管理、容器创建、执行、监控与资源清理。它在 Kubernetes 中通常作为 CRI 插件(via cri-containerd),支持标准的 OCI 容器格式。
例如,我们将运行以下命令来创建一个 Redis 容器,该容器在容器注册表上有一个可用的 Redis 容器镜像,和 Docker 很像是吧。
- 下载镜像:
sudo ctr images pull docker.io/library/redis:latest - 创建容器:
sudo ctr container create docker.io/library/redis:latest redis - 删除容器:
sudo ctr container delete redis - 列出内容:
sudo ctr images list或sudo ctr container list
containerd 的核心组件包括:
- CRI(Container Runtime Interface):Kubernetes 与容器运行时之间的标准接口,containerd 提供 cri 插件,实现了 CRI 兼容能力,使其能被 Kubelet 直接调用。
- Shim(containerd-shim):每个容器对应一个独立的 shim 进程。shim 作为 runc 与 containerd 之间的中介,生命周期独立于 containerd,负责维持容器运行状态、转发 IO 与信号,同时实现容器崩溃时的日志保留。
- runc:符合 OCI 标准的低级容器运行时,用于实际创建和启动容器。每次只在启动容器时被调用,完成后立即退出。
容器从创建到运行的大致过程如下:
- 准备容器环境 containerd 拉取镜像(通过 image service),并解压构建 rootfs,同时准备挂载点和容器目录结构。
- 生成 OCI 配置 根据 Kubernetes PodSpec 等信息,containerd 创建符合 OCI Runtime Spec 的 config.json,描述容器的命名空间、资源限制、挂载、命令等元数据。
- 启动 shim 进程 containerd 启动一个 containerd-shim 实例,该 shim 负责维护容器生命周期。它会持有容器的 stdio 和状态,确保即使 containerd 重启,容器也能持续运行。
- 调用 runc 启动容器 shim 调用 runc create 来根据 config.json 启动容器。当容器运行成功后,runc 进程退出,shim 接管控制。
- 容器运行与管理 shim 转发容器 stdout/stderr,监听状态,并响应 containerd 发起的信号(如 stop/restart)。容器退出后,containerd 和 shim 共同完成资源清理。
4 安全容器技术
传统容器(如使用 runc 的容器)虽然通过 Namespace 和 Cgroup 实现了资源隔离与进程隔离,但所有容器共享同一个宿主机内核,这带来了两个安全隐患:
- 容器逃逸(Container Escape):恶意进程可通过漏洞提升权限,逃出容器并访问宿主机。
- 内核攻击面大:容器数量越多,内核系统调用暴露越多,风险增大。
为此,安全容器技术提出了更强的隔离手段,代表方案有两种主流路径:
| 模型 | 核心理念 | 代表方案 |
|---|---|---|
| 用户态内核(Syscall Sandbox) | 拦截系统调用,构建隔离层 | gVisor |
| 轻量级虚拟化(KVM) | 每个容器运行于微型虚拟机中 | Kata Containers |
4.1 gVisor:用户态内核的沙箱容器
- gVisor 在容器与宿主机内核之间插入一个 用户态内核 Sentry,由 Go 实现。
- 容器的所有系统调用都会被 Sentry 捕获和模拟。
- 这样,容器实际上运行在一个受控、沙箱化的环境中。
Container Process
↓
Syscall (open, read, etc.)
↓
gVisor Sentry (用户态模拟内核逻辑)
↓
部分调用透传给宿主机内核(经过校验)
4.2 Kata Containers:每个容器一个轻量级 VM
- Kata 在每个容器运行时,启动一个轻量级虚拟机,提供独立的 Linux 内核。
- 采用 KVM/QEMU 或 Firecracker 启动极小型 VM,性能接近原生。
Container Process
↓
VM (隔离的 Linux Kernel)
↓
Hypervisor (KVM, QEMU)
↓
Host Kernel
5 Docker 深度解析
5.1 Docker 简介
Docker 是一个开源的容器化平台,基于 Linux 内核的 Namespace 和 Cgroup 技术,提供了一套完整的容器生命周期管理工具,极大地简化了容器的创建、构建、运行、分发和监控流程。
Docker 的设计理念是:将应用及其运行环境打包为标准化的镜像,并以轻量级容器的形式运行于任何兼容平台上,实现 “Build once, Run anywhere”。
Docker 在底层隔离机制之上,抽象出一套易用的用户接口和工作流,包括:
- Docker Engine:负责容器生命周期管理的守护进程。
- Docker Image:容器运行所需的只读模板,包含操作系统、依赖和应用。
- Docker Container:从镜像创建的可运行实例,拥有独立的文件系统、网络和进程空间。
- Dockerfile:定义镜像构建步骤的脚本,使用 DSL 描述每一层变更。
Docker 的优势:
- 易用性:一个命令即可启动隔离环境(如 docker run nginx)。
- 一致性:镜像可在任何平台一致运行。
- 生态活跃:依托 Docker Hub 提供数十万预构建镜像。
- 强隔离性:依赖 Linux Kernel Namespace + Cgroup 实现资源与环境隔离。
Docker 本质上是对 Namespace、Cgroup、UnionFS 等内核特性的高级封装,降低了容器使用门槛,是推动容器化技术普及的关键力量。
5.2 Docker 四层架构模型
Docker 的架构采用分层设计,分为四个主要组件,从上到下分别为:
- Docker Client(客户端)
- 命令行工具或 API 接口,用于接收用户操作(如 docker run);
- 与守护进程通信,默认通过 Unix Socket /var/run/docker.sock。
- Docker Daemon(dockerd)
- 后台运行的核心服务进程;
- 管理镜像、容器、网络、卷、日志等;
- 调用 containerd 实现容器生命周期操作。
- containerd
- 标准的容器运行时,遵循 OCI Runtime Spec;
- 负责容器创建、启动、停止、销毁等;
- 支持镜像管理、容器挂载、Shim 管理等;
- 可独立于 Docker 使用(K8s 默认运行时)。
- runc
- 实际调用 Linux 系统调用创建容器;
- 执行 config.json 中定义的容器规范;
- 每次运行后立即退出,由 Shim 保活。
docker run nginx
↓
Client → Daemon → containerd → containerd-shim → runc → 创建容器
5.3 Docker 网络模型
Docker 提供灵活的网络隔离方案,每个容器默认拥有独立的网络 Namespace。常用网络模式如下:
| 模式 | 描述 |
|---|---|
| bridge(默认) | 每个容器分配 veth 对,通过虚拟网桥 docker0 连接宿主机,与外部通信需 NAT 转换 |
| host | 容器共享宿主机网络 Namespace,无隔离,使用宿主机 IP 和端口 |
| none | 容器保留网络 Namespace,但无网络连接,仅有回环接口(lo) |
| container: | 多容器共享同一容器的网络空间,实现进程级网络复用 |
| overlay(K8s) | 跨主机容器通信,常用于容器编排平台 |
5.4 存储驱动与文件系统
Docker 镜像与容器采用 UnionFS 实现分层文件系统,不同存储驱动对性能和功能有影响。
- Overlay2:推荐驱动,使用 OverlayFS(Linux >= 4.0),LowerDir+UpperDir 组成 MergeDir,性能优异。
6 K8s 核心架构与组件
Kubernetes (K8s) 作为一个开源的容器编排平台,其核心能力在于自动化部署、扩缩容以及管理容器化应用。一个典型的 Kubernetes 集群由控制平面 (Control Plane) 和一个或多个工作节点 (Worker Nodes) 组成。
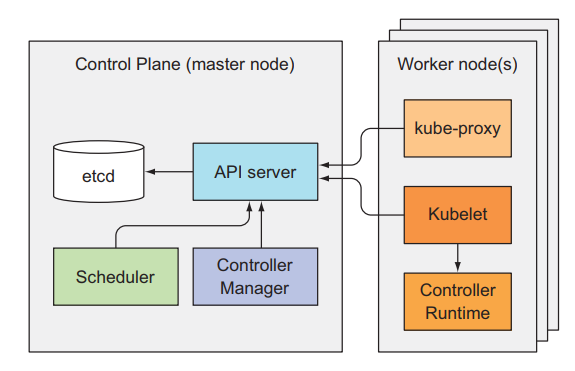
- 控制平面 (Control Plane):可以理解为集群的 " 大脑 “。它负责维护集群的期望状态,包括调度应用、维护应用副本、滚动升级应用、监控集群资源等。所有对集群的操作请求都首先由控制平面处理。
- 工作节点 (Worker Node):是集群中真正运行容器化应用的地方。每个工作节点都由控制平面进行管理,接收控制平面下达的指令,例如创建、启动、停止容器等。
6.1 控制平面 (Control Plane) 核心组件
控制平面是 Kubernetes 集群的管理中心,确保集群按照期望状态运行。它通常包含以下关键组件:
- etcd:
- 作用: 高可用、分布式的键值存储系统。
- 功能: 作为 Kubernetes 集群的唯一可信数据源。集群的所有配置信息、状态数据(如 Pod、Service、Deployment、Secret 等对象的定义和当前状态)都持久化存储在 etcd 中。
- 重要性: etcd 的稳定性和数据一致性对整个集群至关重要。控制平面中的其他组件都通过 API Server 与 etcd 交互。
- API Server (kube-apiserver):
- 作用: Kubernetes 控制平面的核心组件,对外暴露 Kubernetes API。
- 功能:
- 处理来自用户(如通过 kubectl)和集群内部组件的所有 RESTful 请求。
- 负责请求的认证 (Authentication)、授权 (Authorization) 和准入控制 (Admission Control)。
- 验证请求的有效性。
- 将对象的状态变化持久化到 etcd。
- 提供 “Watch” 机制,允许其他组件监听资源的变化,实现组件间的解耦和异步通信。
- 重要性: API Server 是集群各个组件通信的枢纽,也是外部用户与集群交互的唯一入口。
- Controller Manager (kube-controller-manager):
- 作用: 负责运行各种控制器 (Controller)。
- 功能: 控制器是一类监控集群状态并尝试将当前状态调整到期望状态的控制回路 (Control Loop)。Controller Manager 将多个控制器打包运行在一个进程中。
- 常见内置控制器:
- Node Controller: 监控节点的状态。如果节点变得不可用,它会注意到并在适当的时候更新该 Node 对象的状态,并负责将原先运行在该节点上的 Pod 进行 " 垃圾回收 “(由其他控制器如 ReplicaSet Controller 触发重新创建)。
- ReplicaSet Controller: 确保特定 Pod 的副本数量始终符合期望(例如,在一个 Deployment 中,ReplicaSet Controller 负责维护指定数量的 Pod 副本)。
- Deployment Controller: 管理 Deployment 对象,负责创建 ReplicaSet 并处理 Pod 的滚动更新和回滚。
- StatefulSet Controller: 管理 StatefulSet 对象,为 Pod 提供稳定的网络标识和持久存储。
- Job Controller: 运行一次性任务 (Job),确保其按计划完成。
- Endpoint Controller: 填充 Service 和 Pod 之间的 Endpoint 对象,供 kube-proxy 使用。
- 重要性: 控制器是 Kubernetes 实现自动化和自愈能力的关键。
- Scheduler (kube-scheduler):
- 作用: 负责为新创建的、尚未被调度到任何节点上的 Pod 选择一个合适的工作节点。
- 功能:
- 监听 API Server,查找处于
Pending状态的新 Pod。 - 执行调度算法,该算法包含两个主要步骤:
- 过滤 (Filtering): 根据 Pod 的资源需求、节点亲和/反亲和性、污点/容忍度、Pod 中断预算等条件,从所有可用节点中筛选出符合条件的节点列表。
- 排序 (Scoring): 根据预设的优先级函数,对过滤后的节点进行打分,选择得分最高的节点作为最终的调度目标。
- 将 Pod 绑定到选定的节点(通过更新 Pod 的
nodeName字段)。
- 监听 API Server,查找处于
- 重要性: 高效且智能的调度器是集群资源利用率和应用性能的关键保障。
6.2 工作节点(Worker Node)核心组件
工作节点负责运行应用容器,并与控制平面通信。每个工作节点上都运行着以下核心组件:
- Kubelet:
- 作用: 运行在每个工作节点上的主要 " 节点代理 “。
- 功能:
- 接收来自 API Server 的 Pod 定义 (PodSpec)。
- 与容器运行时 (Container Runtime) 交互,根据 Pod 定义创建、启动、停止容器。
- 监控节点上运行的 Pod 和容器的状态,并定期向控制平面报告节点和 Pod 的健康状况、资源使用情况等信息。
- 管理 Pod 的存储卷 (Volumes)。
- 重要性: Kubelet 是控制平面与工作节点上实际运行的容器之间的桥梁。
- Kube-Proxy:
- 作用: 运行在每个工作节点上的网络代理。
- 功能:
- 负责维护节点上的网络规则(如 iptables 或 IPVS 规则),实现 Kubernetes Service 的抽象。
- 根据 Service 和 Endpoint 对象的信息,确保到达 Service IP 的请求能够被正确地路由和转发到后端的 Pod。
- 实现 Service 的负载均衡功能。
- 重要性: Kube-Proxy 使得 Service 能够提供稳定的访问地址,并实现对后端 Pod 的发现和负载均衡,是 Kubernetes 网络模型的核心组成部分。
- Container Runtime:
- 作用: 负责在节点上真正运行容器的软件。
- 功能:
- 拉取容器镜像。
- 解压镜像。
- 创建和管理容器的生命周期(启动、停止、删除)。
- 常见运行时: Docker Engine (通过 shim)、containerd、CRI-O 等。
- 重要性: 容器运行时是执行容器化应用的基础。
6.3 容器运行时接口 (Container Runtime Interface - CRI)
为了使 Kubelet 能够与多种不同的容器运行时进行交互,Kubernetes 定义了 容器运行时接口 (CRI)。
- CRI 的作用: CRI 是一组 gRPC API 接口规范。Kubelet 通过遵循 CRI 接口与容器运行时进行通信,而无需关心底层具体的容器运行时是 Docker、containerd 还是 CRI-O。
- 优势:
- 解耦: 将 Kubelet 与具体的容器运行时实现解耦,提高了 Kubernetes 的灵活性和可插拔性。
- 简化: 使得 Kubelet 的代码更加简洁,无需为每一种容器运行时实现特定的集成逻辑。
- 生态: 允许更多的容器运行时实现者通过实现 CRI 接口来与 Kubernetes 集成。
Kubelet 调用 CRI 接口,由 CRI 实现层(通常是容器运行时自身或其附属组件,如 Docker 的 dockershim)将调用转换为底层容器运行时能够理解的操作(如调用 runc 或 crun 等低级运行时)。
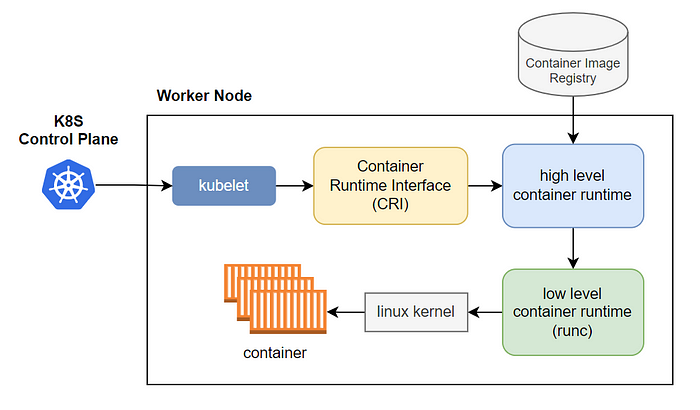
流程简述: 当 Kubelet 需要创建容器时,它通过 CRI 向高级容器运行时(如 containerd 或 CRI-O)发出指令。高级容器运行时负责拉取镜像、管理镜像存储等。然后,高级容器运行时会调用低级容器运行时(如 runc 或 crun),由低级容器运行时负责创建和运行容器进程,设置其命名空间 (namespaces) 和控制组 (cgroups)。
6.4 Kubernetes 工作流程示例
为了更好地理解这些组件如何协同工作,我们通过两个常见场景来串讲其流程:
6.4.1 场景 1: 用户创建 Deployment (例如,创建 3 个 Nginx Pod)
用户通过 kubectl 命令声明期望状态:
kubectl create deployment myapp --image=nginx --replicas=3
这个看似简单的命令背后,Kubernetes 集群执行了以下一系列操作:
- kubectl 发送请求:
kubectl解析用户命令,构建对应的 API 请求(创建一个 Deployment 对象),并将请求发送给 API Server。 - API Server 处理请求:
- API Server 接收请求,进行认证、授权和准入控制检查。
- 验证请求有效后,API Server 将这个新的 Deployment 对象的状态信息写入 etcd 进行持久化。
- API Server 通过 Watch 机制通知相关的组件(如 Deployment Controller)有新的对象被创建或更新。
- Deployment Controller 响应:
- Controller Manager 中的 Deployment Controller 通过 Watch 机制收到 API Server 的通知,检测到新的
myappDeployment 对象。 - Deployment Controller 检查该 Deployment 的期望状态 (
replicas: 3)。发现当前还没有对应的 Pod,状态不匹配。 - 为了达到期望状态,Deployment Controller 创建一个 ReplicaSet 对象,指定其管理的 Pod 模板和期望的副本数 (
replicas: 3),然后将 ReplicaSet 对象写入 etcd。
- Controller Manager 中的 Deployment Controller 通过 Watch 机制收到 API Server 的通知,检测到新的
- ReplicaSet Controller 响应:
- Controller Manager 中的 ReplicaSet Controller 通过 Watch 机制发现新的 ReplicaSet 对象。
- ReplicaSet Controller 检查其期望状态 (
replicas: 3)。发现当前没有与其关联的 Pod,状态不匹配。 - 为了达到期望状态,ReplicaSet Controller 根据 ReplicaSet 中的 Pod 模板,创建 3 个 Pod 对象(初始状态为
Pending,并将这 3 个 Pod 对象写入 etcd。
- Scheduler 调度 Pod:
- Scheduler 通过 Watch 机制发现有 3 个新的、状态为
Pending的 Pod 对象。 - Scheduler 为这 3 个 Pod 逐一执行调度流程:根据 Pod 的资源需求、节点标签、污点、容忍度等信息,通过过滤和打分算法选择最合适的工作节点。
- Scheduler 更新这 3 个 Pod 对象的
nodeName字段,将其绑定到选定的工作节点上,并将更新后的 Pod 对象写入 etcd。通过 Watch 机制通知对应的 Kubelet。
- Scheduler 通过 Watch 机制发现有 3 个新的、状态为
- Kubelet 在节点上创建容器:
- 每个工作节点上的 Kubelet 通过 Watch 机制收到 API Server 的通知,发现有 Pod 对象被调度到 它所在的节点(
nodeName与节点名称匹配)。 - Kubelet 获取 Pod 的详细定义 (PodSpec)。
- Kubelet 调用节点上的 Container Runtime Interface (CRI) 实现(例如 containerd 或 CRI-O)。
- CRI 实现指示底层的 Container Runtime 拉取 Pod 定义中指定的容器镜像(例如
nginx),然后在节点上创建并启动相应的容器。 - 容器启动后,Kubelet 持续监控容器的运行状态,并将 Pod 的状态更新为
Running等,通过 API Server 写入 etcd。
- 每个工作节点上的 Kubelet 通过 Watch 机制收到 API Server 的通知,发现有 Pod 对象被调度到 它所在的节点(
- Kube-Proxy 配置网络:
- 每个工作节点上的 Kube-Proxy 通过 Watch 机制发现新的 Pod(有了 IP 地址)。
- 如果存在指向这些 Pod 的 Service 对象(通常在创建 Deployment 后会创建 Service 以便访问),Kube-Proxy 会根据 Service 和 Pod 的 IP、端口信息,更新节点上的网络规则(如 iptables/IPVS),确保可以通过 Service IP 访问到这些 Pod,并实现负载均衡。
至此,3 个 Nginx Pod 成功运行在集群的工作节点上,并通过 Service 可被访问。
6.4.2 场景 2: 工作节点发生故障
假设承载部分 Pod 的某个工作节点因为硬件故障或网络问题离线:
- Node Controller 检测故障:
- Controller Manager 中的 Node Controller 定期检查集群中各个工作节点的心跳(Kubelet 会定期向 API Server 报告节点状态)。
- 如果 Node Controller 在一段时间内没有收到某个节点的心跳,它会将该节点标记为
NodeReady=Unknown或在更长时间后标记为NodeReady=False。最终,在达到一定的超时时间后(由pod-eviction-timeout控制,默认为 5 分钟),Node Controller 会将该节点上运行的 Pod 标记为需要被驱逐 (evicted)。
- Pod 状态更新:
- 故障节点上的 Pod 状态可能被标记为
Unknown或Terminating。这些 Pod 不再被视为健康或可用。
- 故障节点上的 Pod 状态可能被标记为
- ReplicaSet Controller 调整副本数:
- Controller Manager 中的 ReplicaSet Controller 通过 Watch 机制监测到与其关联的 Pod 数量(健康运行的 Pod)少于期望的副本数(本例中是 3)。
- 为了恢复到期望状态,ReplicaSet Controller 创建新的 Pod 对象(假设是第 4 个 Pod),将其状态设置为
Pending,并写入 etcd。
- 后续流程:
- Scheduler 发现新的
Pending状态的 Pod (Pod4)。 - Scheduler 为其选择一个健康的工作节点进行调度(跳过故障节点)。
- Kubelet 在新的健康节点上接收 Pod 定义,调用 Container Runtime 创建并启动容器。
- Kube-Proxy 在新节点上更新网络规则。
- Scheduler 发现新的
通过这一系列自动化流程,Kubernetes 实现了集群的自愈能力,确保了应用的高可用性,即使底层基础设施出现故障。
核心控制器职责总结:
- Deployment Controller: 管理 Deployment 对象,负责应用的生命周期管理(创建、更新、回滚),通过管理 ReplicaSet 实现。
- ReplicaSet Controller: 确保特定 Pod 的副本数量始终符合期望值,是实现服务水平伸缩和自愈的基础。
- Node Controller: 监控和管理工作节点的状态,处理节点故障。
- Scheduler: 负责为新创建的 Pod 选择合适的运行节点。
- Kubelet: 运行在工作节点上的代理,负责 Pod 和容器的生命周期管理、节点状态报告。
- Kube-Proxy: 负责维护网络规则,实现 Service 的抽象和负载均衡。
这些组件协同工作,共同构成了 Kubernetes 强大的容器编排能力。理解它们的职责和交互方式,是掌握 Kubernetes 的关键。