1 LangGraph 核心速览
定位:面向长期运行(long-running)、有状态(stateful)智能体与复杂工作流的低层编排框架,不遮蔽提示与架构,专注执行、状态与可观测性。
核心价值:Durable(失败可恢复)+ Stateful(结构化状态)+ Human-in-the-loop(可插人审阅/修改)+ Memory(短期推理上下文 + 长期持久存储)+ Observability(轨迹与指标)+ Production(部署与扩展友好)。
快速上手要点:
- 安装后用预构建 create_react_agent(模型 + 工具 + prompt),agent.invoke 进入对话/推理循环。
- 建议路线:Quickstart → 基础教程(自定义图 / 记忆 / 持久执行)→ 进阶设计模式(分支、子图、模板化)。
核心机制心智模型:
- Graph:节点(LLM 调用 / 工具 / 决策 / 人工审批)+ 边(条件/路由)。
- State:序列化可检查/可编辑,支持 checkpoint;用于恢复和调试。
- Runtime:调度节点,遇故障回放到最近 checkpoint 精准续跑。
- Memory:工作记忆维持上下文;长期记忆接入外部存储(向量库 / KV / DB)。
- Observability:与 LangSmith 集成,追踪执行路径、状态转移、耗时与调用指标。
典型场景:
- 多步骤推理(ReAct、Planner-Executor)
- 长周期任务(监控、异步调查、工单处理、运营自动化)
- 人机协同(审批、结果确认、风险把控)
- 高审计需求(金融、合规、客服回放)
2 LangGraph 快速上手:使用预构建组件
本章重点介绍如何利用 langgraph.prebuilt 中的可重用组件,特别是 create_react_agent,来快速构建、配置和扩展一个功能完备的 ReAct 风格智能体。这是掌握 LangGraph 最直接的路径。
2.1 基础创建与调用
通过 create_react_agent 函数可以一步到位地创建一个代理。
- 核心参数:
model: 指定语言模型,可以是字符串标识符(如"anthropic:claude-3-7-sonnet-latest")或一个模型实例。tools: 一个包含智能体可用工具函数的列表。prompt: 智能体的系统级指令,可以是静态字符串。
- 调用:
- 使用
.invoke()方法运行代理。 - 输入是一个字典,必须包含
messages键,其值为一个消息列表(如[{"role": "user", "content": "…"}])。
- 使用
from langgraph.prebuilt import create_react_agent
# 1. 定义工具
def get_weather(city: str) -> str:
"""Get weather for a given city."""
return f"It's always sunny in {city}!"
# 2. 创建代理
agent = create_react_agent(
model="anthropic:claude-3-7-sonnet-latest",
tools=[get_weather],
prompt="You are a helpful assistant"
)
# 3. 调用代理
response = agent.invoke(
{"messages": [{"role": "user", "content": "what is the weather in sf"}]}
)
2.2 配置与定制
2.2.1 配置 LLM 参数
若要对模型进行更精细的控制(如设置 temperature),应先使用 LangChain 的 init_chat_model 创建模型实例,再将其传入。
from langchain.chat_models import init_chat_model
# 初始化模型并设置参数
model = init_chat_model(
"anthropic:claude-3-7-sonnet-latest",
temperature=0
)
# 将模型实例传入
agent = create_react_agent(
model=model,
tools=[get_weather],
)
2.2.2 添加自定义提示 (Prompt)
Prompt 可以是静态的,也可以是动态的,以适应更复杂的场景。
静态 Prompt: 直接提供一个字符串,它将作为固定的系统消息。
agent = create_react_agent( # … prompt="Never answer questions about the weather." )动态 Prompt: 定义一个函数,该函数在运行时生成提示。这对于根据会话状态或外部配置动态调整智能体行为至关重要。
- 函数签名:
def prompt_function(state: AgentState, config: RunnableConfig) -> list[AnyMessage]: state: 包含当前智能体内部状态的字典(如历史消息state["messages"])。config: 包含运行时配置的字典,可通过.invoke()的config参数传入(如user_id、API 密钥等)。
from langchain_core.messages import AnyMessage from langchain_core.runnables import RunnableConfig from langgraph.prebuilt.chat_agent_executor import AgentState def dynamic_prompt(state: AgentState, config: RunnableConfig) -> list[AnyMessage]: user_name = config["configurable"].get("user_name", "User") system_msg = f"You are a helpful assistant. Address the user as {user_name}." # 将动态生成的系统消息与当前对话历史结合 return [{"role": "system", "content": system_msg}] + state["messages"] agent = create_react_agent( # … prompt=dynamic_prompt ) # 调用时传入动态配置 agent.invoke( {"messages": [{"role": "user", "content": "what is the weather in sf"}]}, config={"configurable": {"user_name": "John Smith"}} )- 函数签名:
2.3 启用记忆 (Memory)
为实现多轮对话,必须为代理配置一个 checkpointer。这会使代理在每一步后保存其状态。
- 核心组件:
checkpointer: 一个持久化存储后端实例。InMemorySaver用于快速原型验证,生产环境应使用如SqliteSaver、RedisSaver等。thread_id: 在config中提供,作为对话会话的唯一标识符。
- 工作流程:
- 创建
checkpointer实例。 - 将
checkpointer传入create_react_agent。 - 调用
agent.invoke()时,在config中指定一个thread_id。 - 后续使用相同
thread_id的调用将自动加载之前的对话历史,从而实现上下文连续性。
- 创建
from langgraph.checkpoint.memory import InMemorySaver
checkpointer = InMemorySaver()
agent = create_react_agent(
model="anthropic:claude-3-7-sonnet-latest",
tools=[get_weather],
checkpointer=checkpointer # 启用记忆
)
# 定义会话ID
config = {"configurable": {"thread_id": "session-123"}}
# 第一次调用
agent.invoke(
{"messages": [{"role": "user", "content": "what is the weather in sf"}]},
config=config
)
# 第二次调用(同一会话)
# 代理会自动记起上一轮的对话内容
agent.invoke(
{"messages": [{"role": "user", "content": "what about new york?"}]},
config=config
)
2.4 配置结构化输出 (Structured Output)
如果希望代理的最终响应符合特定的数据结构(而非纯文本),可以配置 response_format。
- 实现方式:
- 定义一个
Pydantic模型或TypedDict作为期望的输出模式。 - 将该模式传递给
create_react_agent的response_format参数。 - 最终的结构化结果将位于返回字典的
structured_response键中。
- 定义一个
- 注意: 这通常会增加一次额外的 LLM 调用,用于将自然语言最终答案格式化为指定的结构。
from pydantic import BaseModel
# 1. 定义输出模式
class WeatherResponse(BaseModel):
conditions: str
temperature_celsius: int
# 2. 创建代理时指定 response_format
agent = create_react_agent(
model="anthropic:claude-3-7-sonnet-latest",
tools=[get_weather],
response_format=WeatherResponse
)
# 3. 调用并获取结构化输出
response = agent.invoke(
{"messages": [{"role": "user", "content": "what is the weather in sf"}]}
)
# 结果是一个 WeatherResponse 对象
structured_data = response["structured_response"]
print(structured_data.conditions)
3 核心工作流模式 (Workflow Patterns)
在 LangGraph 中构建应用时,理解不同的执行模式至关重要。这些模式是从简单的线性流程到复杂的动态决策的基石。本章将探讨几种核心的工作流模式,并解释它们在 LangGraph 中的实现方式。
3.1 工作流 (Workflow) vs. 智能体 (Agent)
首先,我们需要区分两个关键概念:
- 工作流 (Workflow): 指的是通过预定义代码路径来编排 LLM 和工具的系统。流程是固定的、确定性的,类似于传统的流程图。开发者明确定义了每一步的操作和流转条件。
- 智能体 (Agent): 指的是 LLM 动态地指导自己的执行流程和工具使用,拥有对如何完成任务的控制权。流程是不确定的,由模型在运行时根据上下文和目标自主决定。
LangGraph 的强大之处在于其灵活性,它既能构建结构严谨、可预测的工作流,也能支持高度动态、自主决策的智能体。
3.2 构建模块:增强型 LLM (Augmented LLM)
现代 LLM 的两种核心增强能力是构建所有高级工作流的基础:
- 结构化输出 (Structured Output): 通过将一个 Pydantic 模型或
TypedDict绑定到 LLM (llm.with_structured_output(Schema)), 我们可以强制模型的输出遵循预定义的格式。这对于路由决策、数据提取和需要确定性格式的后续步骤至关重要。 - 工具调用 (Tool Calling): 通过将一组工具(函数)绑定到 LLM (
llm.bind_tools([tools])),模型可以自主决定何时需要调用外部函数来获取信息或执行操作,并生成符合函数签名的调用参数。
3.3 核心模式详解
以下是在 LangGraph 中常见的三种核心工作流模式。
3.3.1 A. 提示链 (Prompt Chaining)
- 定义: 将一个复杂任务分解为一系列连续的、线性的步骤。每一步(通常是一次 LLM 调用)处理上一步的输出,逐步精炼或推进任务。
- 适用场景: 当任务可以被清晰地拆解为固定的子任务时。这种模式通过让每个 LLM 调用专注于一个更小、更简单的问题,以牺牲一定的延迟为代价,来换取更高的整体准确性和可靠性。
- 关键实现:
- 线性流程: 使用
workflow.add_edge()将节点按顺序连接。 - 门控 (Gating): 在步骤之间可以插入一个检查节点,用于程序化地验证中间结果的质量。然后使用
workflow.add_conditional_edges()根据检查结果(例如," 通过 " 或 " 失败 “)决定流程是继续、结束还是进入一个修复/改进的分支。
- 线性流程: 使用
- LangGraph 实现要点:
- 定义 State: 使用
TypedDict定义一个状态对象,用于在节点间传递数据,包含每一步的中间和最终结果。 - 定义 Nodes: 每个节点是一个函数,接收当前
state,执行其任务(如调用 LLM),并返回一个字典来更新state。 - 构建图: 使用
StateGraph,通过add_node()添加所有处理节点和检查节点,然后用add_edge()和add_conditional_edges()定义它们之间的流转逻辑。
- 定义 State: 使用
# 示例:一个生成、检查并改进笑话的提示链
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
# 1. 定义状态
class JokeWorkflowState(TypedDict):
topic: str
joke: str
improved_joke: str
final_joke: str
# 2. 定义节点 (函数)
def generate_joke(state: JokeWorkflowState):
# … 调用LLM生成初始笑话 …
return {"joke": "…"}
def check_punchline(state: JokeWorkflowState):
# 简单的程序化检查
if "?" in state["joke"] or "!" in state["joke"]:
return "Pass" # 满足条件,返回 "Pass"
return "Fail" # 不满足,返回 "Fail"
def improve_joke(state: JokeWorkflowState):
# … 调用LLM改进笑话 …
return {"improved_joke": "…"}
def polish_joke(state: JokeWorkflowState):
# … 调用LLM进行最终润色 …
return {"final_joke": "…"}
# 3. 构建图
workflow = StateGraph(JokeWorkflowState)
workflow.add_node("generate_joke", generate_joke)
workflow.add_node("improve_joke", improve_joke)
workflow.add_node("polish_joke", polish_joke)
# 4. 定义流程
workflow.add_edge(START, "generate_joke")
# 添加条件边:根据 check_punchline 的返回值决定下一站
workflow.add_conditional_edges(
"generate_joke",
check_punchline,
{
"Pass": END, # 如果检查通过,流程结束
"Fail": "improve_joke" # 如果失败,进入改进节点
}
)
workflow.add_edge("improve_joke", "polish_joke")
workflow.add_edge("polish_joke", END)
# 5. 编译并执行
chain = workflow.compile()
result = chain.invoke({"topic": "cats"})
3.3.2 B. 并行化 (Parallelization)
- 定义: 多个 LLM 或任务节点同时对一个任务或其不同方面进行处理,最后将它们的输出进行聚合。
- 适用场景:
- 加速: 当任务可以被分解为多个独立的子任务时,并行执行可以显著减少总耗时。
- 提升质量/置信度: 通过让多个模型或使用不同提示的同一模型并行工作(类似 " 投票 " 或 " 专家会审 “),然后综合它们的输出,可以获得更全面、更可靠的结果。
- 关键实现:
- 从
START节点或某个父节点,创建到多个并行任务节点的边。 - LangGraph 会自动并行执行这些没有相互依赖的节点。
- 所有并行分支的输出最终汇集到一个聚合节点 (Aggregator),该节点负责将所有结果整合为单一输出。
- 从
- LangGraph 实现要点:
- 定义 State: 包含所有并行分支需要写入的字段。
- 定义 Nodes: 多个并行处理节点和一个最终的聚合节点。
- 构建图: 从
START节点分别add_edge()到所有并行节点。然后,将所有并行节点add_edge()到同一个聚合节点。
# 示例:并行生成关于同一主题的故事、笑话和诗歌
class ParallelState(TypedDict):
topic: str
story: str
joke: str
poem: str
combined_output: str
# 定义并行节点: call_llm_story, call_llm_joke, call_llm_poem
# …
# 定义聚合节点
def aggregator(state: ParallelState):
combined = (
f"Here's a story, joke, and poem about {state['topic']}!\n\n"
f"STORY:\n{state['story']}\n\n"
f"JOKE:\n{state['joke']}\n\n"
f"POEM:\n{state['poem']}"
)
return {"combined_output": combined}
# 构建图
parallel_workflow = StateGraph(ParallelState)
parallel_workflow.add_node("call_story", call_llm_story)
parallel_workflow.add_node("call_joke", call_llm_joke)
parallel_workflow.add_node("call_poem", call_llm_poem)
parallel_workflow.add_node("aggregator", aggregator)
# 设置并行分支
parallel_workflow.add_edge(START, "call_story")
parallel_workflow.add_edge(START, "call_joke")
parallel_workflow.add_edge(START, "call_poem")
# 汇集到聚合节点
parallel_workflow.add_edge("call_story", "aggregator")
parallel_workflow.add_edge("call_joke", "aggregator")
parallel_workflow.add_edge("call_poem", "aggregator")
parallel_workflow.add_edge("aggregator", END)
chain = parallel_workflow.compile()
3.3.3 C. 路由 (Routing)
- 定义: 首先对输入进行分类,然后根据分类结果将其路由到最合适的专用任务节点或子流程。
- 适用场景: 处理复杂的、多类型的任务。与其用一个庞大而通用的提示来处理所有情况,不如为每种情况设计专门优化过的、更小、更高效的提示或工具链。路由就是实现这种 " 分而治之 " 策略的关键。
- 关键实现:
- 通常流程的第一步是一个路由节点 (Router)。
- 这个路由节点是一个配置了结构化输出的增强型 LLM,其任务就是分析输入并输出一个明确的路由决策(例如,“story”, “joke”, “poem”)。
- 使用
add_conditional_edges,根据路由节点存储在state中的决策,将流程导向相应的下游分支。
- LangGraph 实现要点:
- 定义路由 Schema: 使用 Pydantic 和
Literal定义一个包含所有可能路由选项的 Schema。 - 创建 Router LLM:
router = llm.with_structured_output(RouteSchema)。 - 定义路由节点: 该节点调用
router,并将决策结果(如decision.step)存入state。 - 定义条件路由函数: 一个简单的函数,直接从
state中读取决策并返回,作为add_conditional_edges的依据。
- 定义路由 Schema: 使用 Pydantic 和
# 示例:根据用户请求路由到不同的内容生成器
from typing import Literal
from pydantic import BaseModel
# 1. 定义路由决策的 Schema
class RouteDecision(BaseModel):
step: Literal["poem", "story", "joke"] = Field(description="The next step to take.")
# 2. 创建一个专门用于路由的 LLM
router_llm = llm.with_structured_output(RouteDecision)
# 3. 定义路由节点
def llm_router(state):
# … 调用 router_llm …
decision = router_llm.invoke(…)
return {"decision": decision.step}
# 4. 定义路由逻辑函数
def route_logic(state):
return state["decision"] # 直接返回决策字符串
# 构建图
router_workflow = StateGraph(…)
router_workflow.add_node("router", llm_router)
router_workflow.add_node("write_story", …)
router_workflow.add_node("write_joke", …)
router_workflow.add_node("write_poem", …)
router_workflow.add_edge(START, "router")
# 根据路由逻辑,决定去往哪个节点
router_workflow.add_conditional_edges(
"router",
route_logic,
{
"story": "write_story",
"joke": "write_joke",
"poem": "write_poem",
}
)
# … 将各分支连接到 END …
3.4 智能体架构 (Agent Architectures)
在 LangGraph 中,智能体(Agent)的核心定义是:一个使用 LLM 来决定应用程序控制流程的系统。与写死固定流程的工作流(Workflow)不同,智能体能够动态地选择执行路径、调用工具或判断任务是否完成,从而解决更复杂的问题。
LangGraph 支持从简单到复杂的各类智能体架构,其控制级别各不相同。
3.4.1 路由器 (Router)
路由器是最基础的智能体形态,其控制级别相对有限。
- 核心功能: 允许 LLM 从一组预定义的选项中选择一个后续步骤。它本质上是一个单步决策系统。
- 实现关键: 结构化输出 (Structured Output)。为了让系统能够可靠地解析和执行 LLM 的决策,必须强制 LLM 的输出遵循特定的格式或模式(Schema)。这通常通过以下方式实现:
- 提示工程 (Prompt Engineering): 在提示中明确指示输出格式。
- 输出解析器 (Output Parsers): 对 LLM 的文本输出进行后处理,提取结构化数据。
- 工具调用 (Tool Calling): 利用模型内置的工具调用能力来生成格式化的 JSON 输出,这是最可靠的方式。
3.4.2 通用智能体:ReAct 架构
ReAct 是一种流行的通用智能体架构,它极大地扩展了 LLM 的控制能力,使其能够进行多步决策和与外部世界交互。现代的 ReAct 风格智能体通常整合了以下三个核心概念:
3.4.2.1 A. 工具调用 (Tool Calling)
- 定义: 允许 LLM 根据需要选择并调用外部工具(如 API、数据库查询、代码执行等)。
- 工作原理: 当我们将一个 Python 函数作为工具绑定到模型上时,模型会理解该工具的功能和所需的输入参数。在接收到用户请求后,模型会自主判断是否需要调用工具,并生成符合该工具输入模式的参数。这使得智能体能够获取外部信息或执行具体操作。
3.4.2.2 B. 记忆 (Memory)
- 定义: 使智能体能够在其执行的多个步骤中保留和利用信息,是维持上下文和进行连贯推理的基础。
- 分类:
- 短期记忆: 在单次任务执行序列中,访问先前步骤获取的信息。
- 长期记忆: 回忆起不同交互会话中的信息,例如历史聊天记录。
- LangGraph 实现: LangGraph 提供了对记忆的完全控制。
State: 用户自定义的、用于精确定义需要保留的记忆结构。Checkpointer: 在每一步自动持久化State的机制,实现了跨交互的记忆。Store: 用于存储跨会话的用户特定或应用级数据的机制。
3.4.2.3 C. 规划 (Planning)
- 定义: 在 ReAct 架构中,规划体现为一个循环(while-loop)过程。
- 工作流程:
- LLM 根据当前状态和目标,决定下一步要调用哪个工具。
- 执行该工具。
- 将工具的输出(作为观察结果)反馈给 LLM。
- LLM 评估当前信息是否足以回答最终问题。
- 如果信息不足,则重复步骤 1-4;如果信息充足,则退出循环,生成最终答案。
3.4.3 高级与自定义架构
虽然 ReAct 是强大的通用框架,但针对特定任务定制智能体架构往往能获得更好的性能。LangGraph 提供了构建高级架构所需的功能。
3.4.3.1 A. 人机协同 (Human-in-the-loop)
- 定义: 在智能体的执行流程中引入人工干预点。
- 应用场景: 对于敏感或高风险任务,人类可以进行审批、提供反馈或在复杂决策中给予指导,从而显著提升智能体的可靠性和安全性。
3.4.3.2 B. 并行化 (Parallelization)
- 定义: 同时执行多个独立的任务或处理流程。
- 应用场景: 在多智能体系统中,或当一个复杂任务可以分解为多个独立子任务时,并行化可以极大地提高效率。例如,可以实现 Map-Reduce 这样的操作。LangGraph 通过
SendAPI 支持此功能。
3.4.3.3 C. 子图 (Subgraphs)
- 定义: 在一个大的父图中嵌入模块化的、可独立管理状态的子图。
- 应用场景: 这是管理复杂架构(尤其是多智能体系统)的关键。子图允许为每个智能体隔离状态,构建层级化的团队结构,并控制智能体之间的通信。
3.4.3.4 D. 反思 (Reflection)
- 定义: 智能体具备评估自身工作、进行自我纠错和迭代改进的能力。
- 工作原理: 在一个任务步骤完成后,引入一个 " 反思 " 步骤来评估结果的正确性和完整性。这个评估结果可以作为反馈,指导下一轮的修正或改进。反思机制既可以由另一个 LLM 实现,也可以是确定性的检查(例如,在代码生成任务中,检查代码是否能成功编译)。
4 LangGraph 核心概念:图、状态、节点与边
LangGraph 的核心思想是将复杂的 LLM 应用建模为一个图 (Graph)。理解其底层的三个基本组件是构建任何 LangGraph 应用的基础。
4.1 图 (Graph): 流程的骨架
图是整个工作流的结构。其执行逻辑受到 Google Pregel 系统的启发,采用消息传递的方式运行。
- 核心组件:
- 状态 (State): 一个共享的数据结构,代表了应用在任意时刻的快照。
- 节点 (Node): 执行具体工作的函数(可以包含 LLM 调用,也可以是普通代码)。
- 边 (Edge): 决定流程方向的逻辑,根据当前状态确定下一个要执行的节点。
- 工作原理: 节点完成工作后,通过边将更新后的状态 " 消息 " 传递给下一个节点,接收到消息的节点被激活并执行,如此循环。图的执行在所有节点都变为非活动状态时终止。
- 构建与编译:
- 使用
StateGraph类来定义图。 - 在添加完所有节点和边之后,必须调用
.compile()方法。编译步骤会检查图的结构是否有效(如是否存在孤立节点),并为图附加检查点(Checkpointer)等运行时配置。
- 使用
4.2 状态 (State): 共享的记忆
State 是 LangGraph 的核心,它是所有节点之间共享的数据载体,贯穿整个图的生命周期。
4.2.1 A. 状态模式 (Schema)
定义 State 的结构是构建图的第一步。所有节点和边的输入都是这个 State 对象。
- 定义方式:
TypedDict: 最常用、性能最好的方式。dataclass: 当你需要在状态中提供默认值时使用。Pydantic BaseModel: 当需要递归或复杂的数据校验时使用,但性能稍逊。
- 多模式 (Multiple Schemas):
- 为了使图的接口更清晰,可以为图定义独立的
input_schema和output_schema。 - 节点可以在内部使用未在图输入/输出中暴露的 " 私有 " 状态字段进行通信,增强了模块化和封装性。
- 为了使图的接口更清晰,可以为图定义独立的
from typing_extensions import TypedDict
# 定义图的整体状态结构
class OverallState(TypedDict):
user_input: str
intermediate_step: str
final_output: str
# 可以只把一部分作为图的输入
class InputState(TypedDict):
user_input: str
# 编译时可以指定不同的输入和输出模式
# graph = StateGraph(OverallState, input_schema=InputState, output_schema=…)
4.2.2 B. 归约器 (Reducers)
Reducer 定义了当一个节点返回更新时,这些更新如何合并到全局 State 中。State 中的每一个键 (key) 都有自己独立的 Reducer。
- 默认 Reducer: 覆盖 (Override)。如果一个节点返回
{"foo": 2},那么State中foo的值就会被更新为2,其他键保持不变。 - 自定义 Reducer: 使用
Annotated类型来为特定键指定合并函数。这在处理列表时尤其有用。
from typing import Annotated, List
from typing_extensions import TypedDict
from operator import add
class AgentState(TypedDict):
# foo 的更新会覆盖旧值
foo: str
# messages 的更新会通过 add 函数(列表拼接)合并到旧值
messages: Annotated[List, add]
4.2.3 C. 在状态中使用消息 (Messages in State)
由于现代 LLM 主要通过消息列表进行交互,因此在 State 中维护一个消息列表是极其常见的模式。
add_messagesReducer: LangGraph 提供的预构建 Reducer。它比简单的operator.add更强大,因为它不仅能将新消息追加到列表末尾,还能根据消息的id更新或覆盖列表中已有的消息。这对于实现人机协同(Human-in-the-loop)等需要修改历史记录的场景至关重要。MessagesState: 一个预构建的StateTypedDict,它内置了一个名为messages的键,并已配置好使用add_messages作为 Reducer,可以直接继承使用,非常方便。
from langgraph.graph import MessagesState
# 继承 MessagesState,并添加自定义字段
class MyAgentState(MessagesState):
documents: List[str]
4.3 节点 (Node): 执行工作的单元
节点是图中的基本执行单元,本质上是 Python 函数。
- 定义: 一个节点函数接收
state作为输入,执行其逻辑,然后返回一个字典,该字典包含了对State的更新。 - 添加节点: 使用
graph.add_node("node_name", node_function)将函数添加到图中。 - 特殊节点:
START: 一个特殊的入口点,代表图的开始。从START出发的边定义了图接收到输入后首先执行哪个节点。END: 一个特殊的终点。当流程指向END时,表示该分支的执行结束。当所有活动分支都到达END时,整个图的执行就完成了。
4.4 边 (Edge): 决定流程方向
边连接着节点,定义了 State 在图中的流转路径,即控制流。
- 作用: 决定在一个节点执行完毕后,接下来应该执行哪个节点。
- 类型:
- 固定转换 (Fixed Transitions): 使用
graph.add_edge("source_node", "destination_node")创建一条无条件的边。 - 条件分支 (Conditional Edges): 使用
graph.add_conditional_edges(),根据一个函数的返回值(通常是读取State里的某个决策字段)来动态地决定下一跳的节点。这是实现路由和复杂逻辑的关键。
- 固定转换 (Fixed Transitions): 使用
5 构建图:序列、分支与循环
在掌握了 State、Node 和 Edge 的基本概念后,我们就可以开始使用 LangGraph 的 Graph API 来构建具有实际功能的图。本章将介绍如何组合这些元素来创建常见的流程结构。
5.1 创建基本流程
5.1.1 A. 序列 (Sequence)
最简单的图结构是线性序列,即一个节点接一个节点地顺序执行。
- 实现方式: 使用
builder.add_edge(source_node, destination_node)方法将节点连接起来。 - 入口与出口:
START: 一个特殊的常量,代表图的入口点。使用builder.set_entry_point("node_name")或builder.add_edge(START, "node_name")来定义起始节点。END: 一个特殊的常量,代表图的出口。当流程执行到连接至END的边时,该路径结束。
from langgraph.graph import StateGraph, START, END
# … (定义 State 和 nodes)
builder = StateGraph(State)
builder.add_node("node_1", node_1_func)
builder.add_node("node_2", node_2_func)
builder.add_node("node_3", node_3_func)
# 定义执行顺序:START -> node_1 -> node_2 -> node_3 -> END
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "node_2")
builder.add_edge("node_2", "node_3")
builder.add_edge("node_3", END)
graph = builder.compile()
5.1.2 B. 分支 (Branch)
分支是实现智能体(Agent)动态决策能力的核心。它允许图根据当前的状态 State 来选择不同的执行路径。
- 实现方式: 使用
builder.add_conditional_edges(source_node, condition_function, path_mapping)。source_node: 决策发生的节点。condition_function: 一个函数,它接收当前的State作为输入,并返回一个字符串。这个字符串是path_mapping中的一个键。path_mapping: 一个字典,将condition_function的返回值映射到具体的下一个节点名。
# … (定义 State 和 nodes)
# 条件函数:根据 state 决定下一步去哪里
def should_continue(state: State) -> str:
if state.get("some_value") > 10:
return "end"
else:
return "continue_work"
# … (添加节点)
# 从 'work_node' 出来后,调用 should_continue 函数做决策
builder.add_conditional_edges(
"work_node",
should_continue,
{
"continue_work": "work_node", # 如果返回 "continue_work",则回到 work_node
"end": END # 如果返回 "end",则结束
}
)
5.1.3 C. 循环 (Loop)
循环是 LangGraph 中实现迭代、反思和自我修正等复杂行为的基础。通过将一个条件分支的目标节点指向一个已经执行过的节点,就可以创建一个循环。
在上文 " 分支 " 的例子中,"continue_work": "work_node" 这条路径就创建了一个从 work_node 到其自身的循环。这个循环会一直执行,直到 should_continue 函数返回 "end" 为止。
5.2 高级控制流
LangGraph 提供了一些高级 API 来处理更复杂的流程,如并行计算和简化控制逻辑。
5.2.1 A. Map-Reduce (Send API)
当你需要对一个列表中的每个元素执行相同的操作时(Map),然后将结果汇总(Reduce),Send API 是一个非常强大的工具。它能让你轻松实现并行化处理。
- 实现方式: 在一个节点中,返回
Send(node_name, list_of_items)。node_name: 你想要对每个元素执行操作的节点名。list_of_items: 一个列表,列表中的每个元素都将作为输入,独立地调用一次node_name节点。
- 工作原理:
- 一个 " 分发 " 节点返回
Send对象。 - LangGraph 框架会 " 捕获 " 这个信号,并为
list_of_items中的每一项启动一个node_name节点的并行(或顺序)执行。 - 所有并行任务完成后,它们的输出会被自动收集起来,并更新到
State中,然后流程继续。
- 一个 " 分发 " 节点返回
from langgraph.graph import Send
# … (定义 State 和 nodes)
# 分发节点:将任务列表发送给 'process_item' 节点
def distributor(state: State):
tasks = state.get("tasks_to_process") # e.g., ["item1", "item2", "item3"]
# 为列表中的每个 task 调用 process_item 节点
return Send("process_item", tasks)
# 处理单个任务的节点
def process_item(item: str):
# … 对 item 进行处理
processed_result = f"processed_{item}"
return {"results": [processed_result]} # 返回的 state 更新
# … (构建图)
# 流程: distributor -> process_item (并行) -> aggregator
5.2.2 B. 命令 (Command API)
通常,节点只负责更新状态,而流程跳转由独立的边(特别是条件边)来决定。Command API 打破了这种分离,允许一个节点在返回状态更新的同时,直接命令图跳转到下一个指定的节点。
- 实现方式: 在节点中返回
graph.Command(next_node_name, {"state_update_key": "value"})。 - 使用场景: 当一个节点的内部逻辑已经可以明确决定下一步该去哪里时,使用
Command可以让图的结构更简洁,避免了为这个简单的跳转逻辑再额外定义一个条件函数。
from langgraph.graph import Graph
# … (定义 State 和 nodes)
def my_node(state: State):
# … 执行一些逻辑
if some_condition:
# 更新状态,并直接跳转到 'next_node_A'
return Graph.Command("next_node_A", {"status": "A_path"})
else:
# 更新状态,并直接跳转到 'next_node_B'
return Graph.Command("next_node_B", {"status": "B_path"})
# … (构建图时,my_node 后面不需要再接条件边)
6 流式传输 (Streaming): 实时反馈与透明度
LangGraph 的流式处理系统是构建响应式、透明用户体验的关键。它允许开发者在图(Graph)运行时,实时地将内部发生的变化推送给前端或调用方,而不是等待整个流程执行完毕才返回最终结果。这对于提升用户体验、增强过程透明度至关重要。
6.1 流式处理的核心价值
- 实时反馈: 用户可以即时看到 LLM 正在生成的 token,实现类似 ChatGPT 的打字机效果。
- 过程透明: 将 " 黑盒 " 的执行过程变得可见,让用户了解当前 Agent 或工作流进展到了哪一步(例如,正在调用哪个工具),从而增强信任感。
- 更优体验: 避免了长时间的静默等待,显著提升了应用的交互体验。
6.2 如何启用流式处理
任何编译好的 LangGraph 图(graph)都拥有 .stream() (同步) 和 .astream() (异步) 方法。通过在这两个方法中传入 stream_mode 参数,即可启用流式处理。
# 同步流式处理
for chunk in graph.stream(inputs, stream_mode="updates"):
print(chunk)
# 异步流式处理
async for chunk in graph.astream(inputs, stream_mode="updates"):
print(chunk)
6.3 流式处理模式与实践
LangGraph 支持多种流式传输模式,你可以根据需要选择一种或多种。
6.3.1 A. 流式传输工作流进度 (updates)
这是最常用的模式之一,用于追踪 Agent 或工作流的每一步进展。
- 作用: 在每个图节点(Node)执行完毕后,流式传输该节点对状态(State)所做的增量更新。
- 典型流程: 对于一个典型的 “LLM -> Tool -> LLM” Agent 流程,你会依次收到:
- 第一个 LLM 节点的输出(包含了工具调用请求)。
- 工具节点的输出(包含了工具执行结果)。
- 第二个 LLM 节点的输出(包含了最终的 AI 回复)。
- 示例代码:
# 假设 agent 是一个编译好的 LangGraph 实例
inputs = {"messages": [{"role": "user", "content": "what is the weather in sf"}]}
# 使用 "updates" 模式来观察每一步的状态变化
for chunk in agent.stream(inputs, stream_mode="updates"):
# chunk 的格式会是 { "node_name": {"state_key": "new_value"} }
print(chunk)
print("\n")
# 可能的输出:
# {'agent': {'messages': [AIMessage(content='', tool_calls=[…])]}}
#
# {'action': {'messages': [ToolMessage(content='…', tool_call_id=…)]}}
#
# {'agent': {'messages': [AIMessage(content='The weather in SF is sunny.')]}}
6.3.2 B. 流式传输 LLM Tokens (messages)
此模式专门用于实现打字机效果。
- 作用: 捕获并流式传输由语言模型(LLM)实时生成的 token。这些 token 会附带元数据,指明它们来自哪个节点。
- 示例代码:
# 使用 "messages" 模式来获取 LLM 的 token 流
for chunk in agent.stream(inputs, stream_mode="messages"):
# chunk 是一个 AIMessageChunk 对象
print(chunk.content, end="")
6.3.3 C. 流式传输自定义更新 (custom)
此模式提供了极大的灵活性,允许你在工作流的任何地方(特别是工具内部)发出自定义的进度信号。
- 作用: 仅流式传输由开发者主动发出的、任意格式的用户定义信号。
- 实现方式: 在你的函数(如工具函数)中,通过
langgraph.config.get_stream_writer()获取一个写入器(writer),然后调用它来发送数据。 - 示例代码:
from langgraph.config import get_stream_writer
# 在工具函数内部发送自定义事件
def get_weather(city: str) -> str:
"""Get weather for a given city."""
# 获取当前流的写入器
writer = get_stream_writer()
# 发送任意数据作为自定义事件
writer.write(f"Fetching weather data for city: {city}…")
# … 执行工具的核心逻辑 …
return f"It's always sunny in {city}!"
# … (创建包含此工具的 agent) …
# 使用 "custom" 模式来接收这些自定义事件
for chunk in agent.stream(inputs, stream_mode="custom"):
print(chunk)
# 输出:
# Fetching weather data for city: sf…
注意: 一旦在工具中使用了
get_stream_writer,该工具就与 LangGraph 的执行环境绑定,无法在外部独立调用。
6.4 组合与控制
6.4.1 A. 同时流式传输多种模式
你可以将一个列表传递给 stream_mode 参数,以便同时接收多种类型的更新。
- 作用: 在一个循环中处理所有类型的流式数据,例如同时显示 Agent 进度和 LLM token。
- 示例代码:
stream_modes = ["updates", "messages", "custom"]
for event in agent.stream(inputs, stream_mode=stream_modes):
# event 的格式会是一个元组 (event_type, data)
# event_type 是 'updates', 'messages', 'custom' 中的一个
event_type, data = event
print(f"--- Event: {event_type} ---")
print(data)
print("\n")
6.4.2 B. 禁用流式传输
在某些复杂场景下(如多智能体系统),你可能希望精确控制哪个 Agent 或哪个模型的输出需要被流式传输。LangGraph 允许在模型级别配置禁用个别 token 的流式输出,从而实现更精细的控制。具体方法可查阅相关模型配置文档。
7 持久化 (Persistence): 检查点与状态管理
LangGraph 的持久化层是其最强大的功能之一,它为工作流提供了记忆、可中断性以及容错能力。这一切都通过检查点管理器 (Checkpointer) 实现。当你为图(Graph)配置了检查点管理器后,每一次执行步骤(super-step)之后,图的完整状态都会被保存下来。
这些保存的状态快照被称为检查点 (Checkpoints),它们被组织在一个线程 (Thread) 中。这个机制是实现人机协作、长时间记忆、时间旅行(回溯调试)和故障恢复等高级功能的基础。
7.1 核心概念
7.1.1 A. 检查点管理器 (Checkpointer)
这是持久化功能的核心引擎。在编译图时,你需要提供一个检查点管理器的实例。LangGraph 内置了多种实现,例如用于快速原型和测试的内存检查点管理器 InMemorySaver,以及可以对接数据库(如 SQLite, Postgres)的管理器。
- 作用: 自动在图的每个关键节点执行后,捕获并存储当前的状态快照。
- 配置: 在
compile()方法中传入checkpointer参数即可启用。
from langgraph.checkpoint.memory import InMemorySaver
# 1. 初始化一个检查点管理器(这里使用内存存储)
checkpointer = InMemorySaver()
# 2. 在编译图时传入
graph = workflow.compile(checkpointer=checkpointer)
7.1.2 B. 线程 (Thread)
一个线程可以理解为一次完整的、可追踪的对话或任务执行序列。它由一个唯一的 thread_id 标识。所有与这次执行相关的检查点都会被归档到这个线程下。
- 作用: 隔离不同的执行历史。你可以为每个用户或每个会话创建一个独立的线程。
- 使用: 在调用
.invoke(),.stream()等方法时,必须在config中提供thread_id。
# 每次调用时,通过 thread_id 指定要操作的执行线程
config = {"configurable": {"thread_id": "user-123-session-1"}}
graph.invoke({"input": "some value"}, config=config)
7.1.3 C. 检查点 (Checkpoint)
检查点是图在某个特定时间点的状态快照,它是一个 StateSnapshot 对象。它不仅仅是数据,还包含了图的执行上下文。
- 核心属性:
values: 当前时刻,状态对象(State)中所有通道(channel)的值。next: 一个元组,包含了下一步将要执行的节点的名称。如果为空,表示图执行已结束。config: 与此检查点关联的配置,包括thread_id和自身的checkpoint_id。metadata: 元数据,例如是哪个节点写入了数据 (writes)、当前是第几步 (step) 等。created_at: 检查点创建的时间戳。parent_config: 指向上一个检查点的配置。
7.2 与持久化状态交互
一旦为图配置了检查点管理器,你就可以利用它来读取和操控图的状态历史。
7.2.1 A. 获取当前状态 (get_state)
你可以随时获取某个线程的最新状态快照。
- 方法:
graph.get_state(config) - 用途: 查看工作流执行到哪一步,以及当前的最终结果是什么。
# 获取 "user-123" 线程的最新状态
config = {"configurable": {"thread_id": "user-123"}}
latest_snapshot = graph.get_state(config)
print(latest_snapshot.values)
7.2.2 B. 获取历史状态 (get_state_history)
你可以获取一个线程的完整执行历史,即该线程下的所有检查点列表。
- 方法:
graph.get_state_history(config) - 用途: 用于调试、展示完整的执行步骤、或实现 " 时间旅行 “。返回的列表按时间倒序排列,最新的检查点在最前面。
# 获取 "user-123" 线程的所有历史快照
config = {"configurable": {"thread_id": "user-123"}}
history = list(graph.get_state_history(config))
# history[0] 是最新的快照, history[-1] 是最初的快照
for snapshot in history:
print(f"Step {snapshot.metadata['step']}: Next up is {snapshot.next}")
7.2.3 C. 更新状态 (update_state)
这是实现人机协作 (Human-in-the-loop) 的关键。它允许你直接修改某个线程的状态。
- 方法:
graph.update_state(config, values) - 用途: 强行覆盖状态中的某个值。例如,当 Agent 卡住时,由人来提供正确的信息,然后让 Agent 从这个新状态继续执行。
# 假设 Agent 等待用户提供一个文件名
config = {"configurable": {"thread_id": "user-123"}}
# 用户通过 UI 输入了文件名,我们用它来更新状态
graph.update_state(config, {"filename": "report-final.docx"})
# 之后再调用 invoke,Agent 就会使用这个新的文件名继续工作
graph.invoke(None, config)
7.2.4 D. 时间旅行与回溯 (invoke with checkpoint_id)
你可以让图从历史上的任意一个检查点 " 分叉 " 出一条新的执行路径。
- 方法: 在调用
invoke时,config中除了thread_id,再额外提供一个checkpoint_id。 - 行为: LangGraph 会加载该检查点时的状态。对于该检查点之后的步骤,会重新执行;而对于之前的步骤,则直接 " 重放 " 结果,不会真正再次计算。
- 用途:
- 纠错: 如果发现某一步出错了,可以回到出错前的状态,用
update_state修正数据,然后从该点重新执行。 - 探索不同路径: 从同一个中间状态开始,尝试不同的输入或分支。
- 纠错: 如果发现某一步出错了,可以回到出错前的状态,用
# 从历史记录中找到一个想要回溯的检查点
history = list(graph.get_state_history(config))
target_checkpoint = history[2] # 假设我们想从第2步之后重新开始
# 构建包含 checkpoint_id 的配置
replay_config = {
"configurable": {
"thread_id": "user-123",
"checkpoint_id": target_checkpoint.config["configurable"]["checkpoint_id"]
}
}
# (可选) 在回溯前先更新状态
graph.update_state(replay_config, {"some_value": "a_new_corrected_value"})
# 从该检查点继续执行,会产生一条新的历史分支
graph.invoke(None, replay_config)
通过这套持久化机制,LangGraph 将原本无状态、一次性的函数调用,转变成了有状态、可追溯、可干预的强大工作流。
8 持久化执行 (Durable Execution): 容错、中断与恢复
持久化执行是 LangGraph 的一项核心能力,它允许工作流在关键点保存其进度,从而可以随时暂停,并在未来从中断处精确恢复。这项技术是实现人机协作(Human-in-the-loop)、处理可能中断或出错的长时任务(如 LLM 调用超时)的基石。
简单来说,如果你已经为你的图(Graph)配置了检查点管理器(Checkpointer),那么你就已经启用了持久化执行。它确保了工作流的每一步状态都被保存到持久化存储中。如果工作流被中断——无论是系统故障还是人为干预——它都可以从最后记录的状态恢复,而无需重新执行已经完成的步骤。
8.1 实现持久化执行的三个要求
要利用 LangGraph 的持久化执行能力,你需要遵循以下三个核心要求:
- 启用持久化: 在编译图时,通过
checkpointer参数指定一个检查点管理器。 - 指定线程: 在执行工作流时(如调用
.invoke()或.stream()),必须在config中提供一个thread_id,用于追踪该工作流实例的执行历史。 - 隔离副作用: 将所有非确定性操作(如生成随机数)或有副作用的操作(如 API 调用、文件写入)封装在**节点(Nodes)或任务(Tasks)**中。这是确保工作流能够被一致地重放和恢复的关键。
8.2 确定性与一致性重放 (Determinism and Consistent Replay)
理解 LangGraph 的恢复机制至关重要:当一个工作流恢复时,代码不会从中断的那一行代码继续执行。相反,它会从最近的一个检查点开始,重放 (replay) 该检查点之后的所有步骤,直到达到中断点。
这个 " 重放 " 机制意味着,如果你的节点函数中包含非确定性代码或副作用,它们可能会在恢复过程中被再次执行,导致意想不到的结果(例如,重复向用户发送邮件、重复写入数据库)。
解决方案:
为了保证工作流的确定性和可预测性,请遵循以下准则:
- 避免重复工作: 如果一个节点包含多个有副作用的操作(例如,多个 API 调用),应将每个操作封装成一个独立的
@task。这样,当工作流恢复时,已经成功完成的任务会直接从持久化层获取结果,而不会被重复执行。 - 封装非确定性操作: 将任何可能产生不确定结果的代码(如调用 LLM、生成随机数)封装在独立的节点或
@task中。这确保了在恢复时,工作流能够以完全相同的步骤和结果进行重放。 - 使用幂等操作: 尽可能确保你的副作用操作是幂等的。这意味着一个操作无论执行一次还是多次,结果都相同。这对于数据写入操作尤为重要。如果一个任务启动后失败,恢复过程会重新运行该任务,幂等性可以防止产生重复数据。
8.3 持久化模式 (Durability Modes)
LangGraph 提供了三种持久化模式,允许你在性能和数据一致性之间进行权衡。你可以在调用图的执行方法时,通过 durability 参数来指定。
| 模式 | 描述 | 优点 | 缺点 |
|---|---|---|---|
"exit" | 仅在图执行完成(成功或失败)时,才持久化状态。 | 性能最高,开销最小。 | 无法从中间步骤的失败中恢复,不支持中断。 |
"async" | 异步持久化。在执行下一步的同时,将当前检查点写入存储。 | 性能和持久性的良好平衡。 | 在极少数情况下,如果进程在写入完成前崩溃,检查点可能会丢失。 |
"sync" | 同步持久化。在开始下一步之前,等待当前检查点完全写入存储。 | 持久性最高,数据最安全。 | 性能开销较大,因为每一步都需要等待 I/O 操作。 |
如何使用:
# 在调用时指定持久化模式
graph.stream(
{"input": "test"},
config={"configurable": {"thread_id": "some-thread"}},
durability="sync" # 可选 "exit", "async", "sync"
)
注意:
durability参数在 v0.6.0 中引入,用于替代旧的checkpoint_during参数。
8.4 在节点中使用任务 (@task)
当一个节点需要执行多个独立的、有副作用的操作时,使用 @task 装饰器是最佳实践。
场景: 假设一个节点需要遍历一个 URL 列表,并为每个 URL 调用一次 API。
- 不使用
@task的问题: 如果在处理到第三个 URL 时 API 调用失败,整个工作流中断。当恢复时,整个节点函数会从头开始执行,前两个已经成功的 API 调用会被重复执行。 - 使用
@task的解决方案: 将 API 调用函数用@task装饰。在节点中,调用这个被装饰的函数。LangGraph 会将每次@task调用视为一个独立的、可检查点化的子步骤。当恢复时,LangGraph 会从检查点加载前两个任务的成功结果,并只重新尝试失败的第三个任务。
示例:
from langgraph.func import task
import requests
# 1. 将有副作用的操作封装成一个 @task
@task
def _make_request(url: str):
"""一个独立的、有副作用的任务"""
return requests.get(url).text[:100]
# 2. 在节点中调用这些任务
def call_multiple_apis(state: State):
"""一个节点,执行多个API请求"""
# LangGraph 会追踪每个 _make_request 的调用
requests = [_make_request(url) for url in state['urls']]
# .result() 会等待任务完成并获取结果
results = [request.result() for request in requests]
return {"results": results}
通过这种方式,即使节点内部的逻辑很复杂,持久化执行机制也能精确地恢复到失败的那个子任务,从而实现真正的容错和高效恢复。
9 LangGraph 笔记:记忆 (Memory)
在 AI 应用中,记忆是跨多次交互共享上下文的关键。对于 Agent 而言,记忆使其能够记住先前的交互、从反馈中学习并适应用户偏好。LangGraph 将记忆系统分为两种核心类型。
- 短期记忆 (Short-term Memory): 线程范围 (thread-scoped) 的记忆,用于在单次会话中跟踪持续的对话历史。
- 长期记忆 (Long-term Memory): 跨会话、跨线程共享的用户特定或应用级数据。
9.1 一、短期记忆 (Short-term Memory)
短期记忆让应用能够记住单次对话或单个线程内的交互历史。这对于实现多轮对话至关重要。
9.1.1 核心概念
- 作用域: 仅限于单个
thread_id。不同的线程拥有独立的对话历史。 - 实现方式: 短期记忆是 Agent 状态 (State) 的一部分。通过配置检查点管理器 (Checkpointer),LangGraph 会将每个步骤后的状态持久化到数据库中。当一个线程恢复时,它可以读取之前的状态,从而 " 记起 " 对话的上下文。
- 典型用例: 存储对话消息列表 (
messages),也可以包含上传的文件、检索到的文档等会话内的临时数据。
9.1.2 如何实现短期记忆
实现短期记忆的核心在于为你的图 (Graph) 配置一个 checkpointer,并在调用时提供一个唯一的 thread_id。
编译时指定 Checkpointer:
- 对于开发和测试,可以使用
InMemorySaver。 - 对于生产环境,必须使用持久化的检查点管理器,如
PostgresSaver、SqliteSaver或RedisSaver。
- 对于开发和测试,可以使用
调用时指定 Thread ID:
- 在调用
.invoke(),.stream(),.astream()等方法时,通过config参数传入{"configurable": {"thread_id": "…"}}。
- 在调用
示例:使用 Postgres 实现持久化的短期记忆
import asyncio
from langgraph.graph import StateGraph, MessagesState, START
from langgraph.checkpoint.postgres import PostgresSaver # 异步版本为 AsyncPostgresSaver
from langchain_openai import ChatOpenAI
# 1. 初始化模型和检查点管理器
model = ChatOpenAI(model="gpt-4o")
DB_URI = "postgresql+psycopg://user:pass@host:port/db"
checkpointer = PostgresSaver.from_conn_string(DB_URI)
# 异步版本: checkpointer = AsyncPostgresSaver.from_conn_string(DB_URI)
# 第一次使用时需要创建表结构
# sync: checkpointer.setup()
# async: await checkpointer.setup()
# 2. 定义图的状态和节点
class MyState(MessagesState):
# 可以根据需要在这里添加更多状态字段
pass
def call_model(state: MyState):
response = model.invoke(state["messages"])
return {"messages": [response]}
# 3. 构建图,并在编译时传入 checkpointer
builder = StateGraph(MyState)
builder.add_node("call_model", call_model)
builder.set_entry_point("call_model")
builder.set_finish_point("call_model")
graph = builder.compile(checkpointer=checkpointer)
# 4. 使用唯一的 thread_id 调用图
config = {"configurable": {"thread_id": "user_123_conversation_456"}}
# 第一次调用
response = graph.invoke({"messages": [{"role": "user", "content": "你好,我叫 Bob"}]}, config=config)
print(response['messages'][-1].content)
# 第二次调用,LangGraph 会自动加载 thread_id="user_123_conversation_456" 的历史
response = graph.invoke({"messages": [{"role": "user", "content": "我的名字是什么?"}]}, config=config)
print(response['messages'][-1].content) # 模型会回答 "Bob"
9.1.3 短期记忆的管理挑战
随着对话变长,完整的历史记录可能会超出 LLM 的上下文窗口,或因包含过时信息而降低模型性能并增加成本。因此,需要采用策略来管理消息历史,例如:
- 仅保留最近的 K 条消息。
- 对早期的消息进行总结。
- 根据相关性过滤消息。
9.2 二、长期记忆 (Long-term Memory)
长期记忆允许系统在不同的对话或会话之间保留信息。它不是绑定到单个线程,而是存储在自定义的命名空间 (namespaces) 中,可以随时随地被任何线程调用。
9.2.1 长期记忆的核心框架
在设计长期记忆时,需要考虑两个核心问题:
- 记忆的类型是什么? (What)
- 何时更新这些记忆? (When)
9.2.2 长期记忆的类型
借鉴人类记忆的分类,AI Agent 的长期记忆可以分为:
语义记忆 (Semantic Memory): 事实
- 用途: 存储关于用户、实体或概念的特定事实,以实现个性化。例如,记住用户的偏好、公司组织架构等。
- 管理方式:
- 档案 (Profile): 将所有信息保存在一个持续更新的 JSON 文档中。
- 优点: 信息集中,上下文完整。
- 缺点: 随着档案变大,更新容易出错,可能需要复杂的 JSON Patch 操作和严格的模式验证。
- 集合 (Collection): 将每条记忆作为独立的文档存储在一个列表中。
- 优点: 新增信息简单,不易丢失数据,LLM 生成新对象比修改大对象更容易。
- 缺点: 更新和删除操作更复杂;需要有效的搜索机制(如语义搜索、内容过滤)来检索相关记忆。
- 档案 (Profile): 将所有信息保存在一个持续更新的 JSON 文档中。
情景记忆 (Episodic Memory): 经验
- 用途: 记录过去的事件或行为序列,帮助 Agent " 学习 " 如何完成任务。
- 实现方式: 最常见的实现是小样本提示 (Few-shot Prompting)。将成功的交互示例(经验)存储起来,在处理新任务时,检索最相关的示例并放入提示中,以 " 展示 " 给 LLM 如何行动。
- 存储: 可以使用 LangGraph 的
Store,也可以使用LangSmith Dataset等工具来存储和检索小样本示例。
程序记忆 (Procedural Memory): 规则
- 用途: 记录执行任务的规则和指令。
- 实现方式: 通常通过修改 Agent 的提示 (Prompt) 来实现,尤其是系统提示。这种方法被称为**” 反思 " (Reflection)** 或元提示 (meta-prompting)。Agent 可以根据最近的对话或用户反馈来反思并优化自己的指令。
- 示例: Agent 在与用户交互后,一个专门的节点 (
update_instructions) 读取当前指令、用户反馈,然后调用 LLM 生成一套更优的指令,并将其写回长期记忆库,供后续任务使用。
9.2.3 写入记忆的时机
实时写入 (In the Hot Path)
- 描述: 在响应用户的过程中,由 Agent 决定是否以及如何写入记忆。例如,通过调用一个
save_memory工具。 - 优点: 记忆立即可用,过程透明。
- 缺点: 增加了 Agent 的任务复杂度和响应延迟。
- 描述: 在响应用户的过程中,由 Agent 决定是否以及如何写入记忆。例如,通过调用一个
后台写入 (In the Background)
- 描述: 将记忆的生成和写入作为一个独立的后台任务异步执行。
- 优点: 不影响主应用延迟,逻辑分离,Agent 可以更专注于核心任务。
- 缺点: 记忆更新有延迟,可能导致其他线程无法立即获取最新上下文;需要设计合理的触发机制(如定时、手动触发等)。
9.2.4 长期记忆的存储与实现
LangGraph 使用 Store 来存储长期记忆。每个记忆都是一个 JSON 文档。
- 组织方式: 通过
(namespace, key)来组织。namespace: 一个元组,类似于文件夹路径,通常包含用户 ID、组织 ID 等,用于隔离和组织数据。例如('user_123', 'chitchat')。key: 字符串,类似于文件名,唯一标识一个记忆项。
- 核心操作:
store.put(namespace, key, value): 存储或更新一个记忆。store.get(namespace, key): 按键获取一个记忆。store.search(namespace, query=…, filter=…): 在指定命名空间内进行搜索。支持基于向量的语义搜索和基于内容的过滤。
示例:使用 Store 存取长期记忆
from langgraph.store.memory import InMemoryStore
# 实际应用中应使用持久化的 Store,如 PostgresStore
# 需要一个嵌入函数来进行语义搜索
def embed_texts(texts: list[str]) -> list[list[float]]:
# 这是一个伪实现,实际应替换为真实的嵌入模型
return [[i * 0.1] * 10 for i, _ in enumerate(texts)]
# 初始化 Store
store = InMemoryStore(index={"embed": embed_texts, "dims": 10})
# 定义命名空间和键
user_id = "user_123"
namespace = (user_id, "preferences")
key = "communication_style"
# 写入一条语义记忆 (事实)
store.put(
namespace,
key,
{
"rules": ["User likes short, direct language", "User only speaks English & python"],
"source": "Initial onboarding",
},
)
# 1. 直接获取记忆
item = store.get(namespace, key)
print(item.value)
# 输出: {'rules': ['User likes short, direct language', …], 'source': 'Initial onboarding'}
# 2. 在命名空间内进行搜索
# 通过语义相似度搜索与 "language preferences" 相关的记忆
search_results = store.search(namespace, query="language preferences")
for result in search_results:
print(result.value)
10 LangGraph 笔记:上下文工程 (Context Engineering)
上下文工程 (Context Engineering) 是一门构建动态系统的实践,其核心目标是:以正确的格式,提供正确的信息和工具,从而使 AI 应用能够高效地完成任务。它不仅仅是关于构建提示(Prompt Engineering),更是关于为 Agent 运行提供所需的一切环境信息。
10.1 上下文的维度 (Dimensions of Context)
我们可以从两个关键维度来理解上下文:
可变性 (Mutability):
- 静态上下文 (Static Context): 在单次图执行期间不可变的数据。例如:用户信息、数据库连接、API 密钥、可用的工具列表。
- 动态上下文 (Dynamic Context): 在应用运行时可变的数据。例如:对话历史、工具调用的中间结果、从大模型输出中提取的值。
生命周期 (Lifetime):
- 运行时上下文 (Runtime Context): 仅限于单次运行或调用范围内的数据。
- 跨对话上下文 (Cross-conversation Context): 能够跨越多次对话或会话持久化存在的数据。
重要区分:运行时上下文 vs. LLM 上下文
- 运行时上下文 (Runtime Context) 指的是你的代码运行所需的本地数据和依赖。
- LLM 上下文 (LLM Context) 指的是最终被传入大模型提示 (Prompt) 的数据。 运行时上下文可以用来优化 LLM 上下文。例如,你可以使用运行时上下文中的用户 ID 来从数据库中获取用户偏好,然后将这些偏好信息填入 LLM 的提示中。
10.2 LangGraph 中的上下文管理
LangGraph 结合了以上维度,提供了三种核心的上下文管理机制。
| 上下文类型 | 可变性 | 生命周期 | LangGraph 实现机制 |
|---|---|---|---|
| 静态运行时上下文 | 静态 (Immutable) | 运行时 (Runtime) | context 参数 |
| 动态运行时上下文 | 动态 (Mutable) | 运行时 (Runtime) | State 对象 |
| 跨对话上下文 | 动态 (Mutable) | 跨对话 (Cross-conversation) | Store (长期记忆) |
10.3 静态运行时上下文 (Static Runtime Context)
这是指在图的单次执行中保持不变的数据。它非常适合传递那些 " 一次性 " 配置信息。
- 特点:
- 在单次
invoke/stream期间不可变。 - 非常适合传递用户元数据、API 密钥、工具集、数据库连接等。
- 在单次
- 如何实现:
- 在调用图时,通过
context参数传入一个字典。 - 注意: 这是 LangGraph v0.6 引入的新模式,取代了之前将配置放在
config['configurable']中的做法。
- 在调用图时,通过
- 如何访问:
- 在节点 (Node) 或工具 (Tool) 内部,使用
langgraph.runtime.get_runtime()函数来获取。 - 推荐使用
dataclass或Pydantic模型来定义context的结构,以获得类型提示和校验。
- 在节点 (Node) 或工具 (Tool) 内部,使用
示例:在节点和工具中访问静态上下文
from dataclasses import dataclass
from langgraph.graph import StateGraph
from langgraph.runtime import get_runtime, Runtime
from typing import TypedDict, Annotated
# 1. 定义上下文的结构
@dataclass
class MyContext:
user_name: str
api_key: str
# 2. 定义图的状态
class MyState(TypedDict):
some_value: str
# 3. 在节点中访问上下文
# 方法一:使用 get_runtime()
def my_node_one(state: MyState):
runtime = get_runtime(MyContext)
user = runtime.context.user_name
print(f"Node One: Hello, {user}!")
return {"some_value": f"Data for {user}"}
# 方法二:通过类型提示 config 参数 (更现代的方式)
def my_node_two(state: MyState, config: Runtime[MyContext]):
user = config.context.user_name
api_key = config.context.api_key
print(f"Node Two: Processing for {user} with key starting with {api_key[:4]}…")
return {}
# 4. 构建图
builder = StateGraph(MyState)
builder.add_node("node1", my_node_one)
builder.add_node("node2", my_node_two)
builder.set_entry_point("node1")
builder.add_edge("node1", "node2")
builder.set_finish_point("node2")
graph = builder.compile()
# 5. 调用图时传入 context
graph.invoke(
{"some_value": "initial"},
context={"user_name": "Alice", "api_key": "sk-12345678"}
)
10.4 动态运行时上下文 (Dynamic Runtime Context / State)
这是指在单次图执行期间可以演变和变化的数据。
- 特点:
- 本质上,这就是 LangGraph 的短期记忆机制。
- 它通过图的
State对象进行管理。 State中的任何字段都可以在图的执行过程中被节点读取和更新。
- 如何实现:
- 定义一个
TypedDict或继承自MessagesState的类作为图的状态模式 (State Schema)。 - 节点接收当前状态作为输入,并返回一个字典来更新状态。
- 定义一个
- 如何访问:
State对象直接作为节点的第一个参数传入。
示例:通过 State 管理动态上下文
from typing import TypedDict, List
from langgraph.graph import StateGraph
class AgentState(TypedDict):
user_name: str
steps_taken: List[str]
def identify_user(state: AgentState):
# 假设此节点从初始消息中识别用户
user = "Bob" # 伪代码
return {"user_name": user, "steps_taken": ["Identified User"]}
def perform_action(state: AgentState):
user = state["user_name"]
print(f"Performing action for user: {user}")
current_steps = state["steps_taken"]
return {"steps_taken": current_steps + ["Performed Action"]}
builder = StateGraph(AgentState)
builder.add_node("identify", identify_user)
builder.add_node("action", perform_action)
# … 设置边和流程 …
10.5 跨对话上下文 (Cross-Conversation Context)
这是指需要跨越多次运行、持久化存在的数据。
- 特点:
- 这是 LangGraph 的长期记忆机制。
- 它允许 Agent 记住跨会话的用户偏好、历史交互摘要等信息。
- 如何实现:
- 通过 LangGraph 的 Store API 来实现。
- 数据被存储在自定义的命名空间 (namespaces) 中,可以被任何线程随时存取。
- 如何访问:
- 这部分内容与上一章 ” 记忆 (Memory)” 紧密相关。
Store的使用,包括put,get,search等操作,是管理跨对话上下文的核心。请参考 " 记忆 (Memory)" 章节获取详细的实现方法和代码示例。
- 这部分内容与上一章 ” 记忆 (Memory)” 紧密相关。
11 LangGraph 笔记:模型 (Models)
在 LangGraph 中,大型语言模型 (LLM) 是智能代理 (Agent) 和工作流的大脑。LangGraph 通过与 LangChain 的无缝集成,可以轻松地使用市面上几乎所有主流的 LLM。
11.1 初始化模型
在 LangGraph 中使用模型的第一步是初始化一个模型实例。主要有两种方式:通用的 init_chat_model 函数和直接实例化模型类。
11.1.1 通用初始化 (init_chat_model)
这是最推荐、最便捷的方式。langchain.chat_models.init_chat_model 函数提供了一个统一的接口,只需通过一个字符串就能初始化不同提供商的模型。
- 格式: 字符串通常遵循
provider:model_name的格式。 - 优势: 无需关心每个提供商具体的类名和导入路径,让代码更具通用性,方便切换模型。
常见模型初始化示例:
from langchain.chat_models import init_chat_model
import os
# 设置你的 API 密钥
# os.environ["OPENAI_API_KEY"] = "sk-…"
# os.environ["ANTHROPIC_API_KEY"] = "sk-…"
# os.environ["GOOGLE_API_KEY"] = "…"
# 初始化 OpenAI 模型
llm_openai = init_chat_model("openai:gpt-4o")
# 初始化 Anthropic 模型
llm_anthropic = init_chat_model("anthropic:claude-3-5-sonnet-latest")
# 初始化 Google Gemini 模型
llm_google = init_chat_model("google_genai:gemini-2.0-pro")
# 初始化 Azure OpenAI 模型 (需要更多环境变量)
# os.environ["AZURE_OPENAI_API_KEY"] = "…"
# os.environ["AZURE_OPENAI_ENDPOINT"] = "…"
# os.environ["OPENAI_API_VERSION"] = "…"
# os.environ["AZURE_OPENAI_DEPLOYMENT_NAME"] = "my-gpt4-deployment"
llm_azure = init_chat_model(
"azure_openai:gpt-4o",
azure_deployment=os.environ.get("AZURE_OPENAI_DEPLOYMENT_NAME"),
)
11.1.2 直接实例化
当 init_chat_model 不支持某个模型提供商,或者你需要对模型进行更精细的参数配置时,可以直接从相应的库中导入并实例化模型类。
- 要求: 实例化的模型必须实现 LangChain 的
BaseChatModel接口。 - 工具调用: 如果你的 Agent 需要使用工具,请确保选择的模型原生支持工具调用 (Tool Calling) 功能。
示例:直接实例化 Anthropic 模型
from langchain_anthropic import ChatAnthropic
# 直接实例化并配置更多参数
model = ChatAnthropic(
model="claude-3-5-sonnet-latest",
temperature=0,
max_tokens=2048,
# … 其他 Anthropic 特定参数
)
11.2 在 Agent 中使用模型
LangGraph 的预构建 Agent(如 create_react_agent)极大地简化了模型的使用。
11.2.1 静态模型分配
你可以直接将模型实例或模型名称字符串传递给 Agent。
from langgraph.prebuilt import create_react_agent
from langchain_anthropic import ChatAnthropic
# 方法 1: 使用模型名称字符串 (推荐,最简洁)
# LangGraph 会在内部调用 init_chat_model
agent_v1 = create_react_agent(
model="anthropic:claude-3-5-sonnet-latest",
tools=[…],
)
# 方法 2: 传入已实例化的模型对象
# 这种方式让你可以在创建 Agent 前对模型进行详细配置
model_instance = ChatAnthropic(model="claude-3-5-sonnet-latest", temperature=0)
agent_v2 = create_react_agent(
model=model_instance,
tools=[…],
)
11.2.2 动态模型选择
这是一个非常强大的高级功能,允许你在运行时 (runtime) 根据特定条件动态选择使用哪个模型。例如,简单的任务使用快速、便宜的模型,复杂的任务切换到功能更强大的模型。
- 实现方式: 将一个可调用对象 (callable),通常是一个函数,传递给
create_react_agent的model参数。 - 函数要求:
- 该函数必须接收
state作为参数。 - 函数必须返回一个
BaseChatModel的实例。 - 关键: 如果你使用了工具,必须在函数内部将工具绑定到所选择的模型上 (
model.bind_tools(tools))。
- 该函数必须接收
示例:根据用户偏好动态选择模型
from langgraph.prebuilt import create_react_agent, AgentState
from langchain.chat_models import init_chat_model
from langchain_core.tools import tool
from typing import TypedDict, Annotated, Literal
# 假设这是一个工具
@tool
def get_weather(city: str):
"""Gets the weather for a city."""
return f"The weather in {city} is sunny."
tools = [get_weather]
# 1. 定义包含模型偏好的 State
class DynamicAgentState(AgentState):
model_preference: Literal["fast", "quality"]
# 2. 定义模型选择函数
def model_selector(state: DynamicAgentState):
"""
根据 state 中的 model_preference 动态选择模型。
"""
preference = state.get("model_preference")
if preference == "fast":
print("--- Selecting FAST model ---")
model = init_chat_model("anthropic:claude-3-haiku-20240307")
else: # 默认为 quality
print("--- Selecting QUALITY model ---")
model = init_chat_model("anthropic:claude-3-5-sonnet-latest")
# 关键:必须在选择后绑定工具
return model.bind_tools(tools)
# 3. 创建 Agent 时传入选择器函数
agent = create_react_agent(
model=model_selector,
tools=tools, # 这里的 tools 列表主要用于 Agent 内部逻辑,绑定发生在 selector 中
state_schema=DynamicAgentState,
)
# 4. 调用时,根据传入的 state 动态选择模型
# 使用快速模型
fast_input = {"messages": [("user", "hi")], "model_preference": "fast"}
for chunk in agent.stream(fast_input):
print(chunk)
# 使用高质量模型
quality_input = {"messages": [("user", "what's the weather in SF?")], "model_preference": "quality"}
for chunk in agent.stream(quality_input):
print(chunk)
12 LangGraph 笔记:工具 (Tools)
在许多 AI 应用中,模型需要与外部世界进行交互,例如查询数据库、调用 API 或访问文件系统。工具 (Tools) 是实现这种交互的核心机制。
一个工具本质上是一个可调用函数及其输入模式(schema)的封装。通过将工具提供给兼容的语言模型,模型能够理解每个工具的功能、何时需要调用它,以及如何为其生成符合规范的输入参数。
12.1 工具调用的核心理念
工具调用的流程可以分为两个关键步骤:
模型的决策 (Decision): 当模型接收到用户输入时,它会分析输入内容并结合其可用的工具列表。
- 如果输入与某个工具有关,模型会生成一个工具调用请求 (tool call request)。这个请求包含在返回的
AIMessage对象的tool_calls字段中,明确指定了要调用的工具名称和参数。 - 如果输入与任何工具都无关,模型将仅返回自然的语言回复。
- 关键点:模型本身不执行工具,它只负责生成调用请求。
- 如果输入与某个工具有关,模型会生成一个工具调用请求 (tool call request)。这个请求包含在返回的
运行时的执行 (Execution): 一个独立的执行器(例如 LangGraph 中的
ToolNode或 Agent)负责接收模型的工具调用请求,实际运行相应的函数,并将执行结果返回给模型,以便模型可以根据结果进行下一步的思考或生成最终答复。

12.1.1 定义工具
定义自定义工具最简单直接的方法是使用 langchain_core.tools 中的 @tool 装饰器。
- 函数签名: 函数的类型注解 (type hints) 会被用来推断工具的输入模式。
- 文档字符串 (Docstring): 函数的文档字符串会成为工具的描述,模型将依赖这个描述来判断何时使用该工具。因此,编写清晰、准确的描述至关重要。
示例:定义一个乘法工具
from langchain_core.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""
将两个整数 a 和 b 相乘。
Multiply two integers a and b.
"""
return a * b
# 定义好的工具符合 Runnable 接口,可以独立调用
result = multiply.invoke({"a": 6, "b": 7})
print(result)
# 输出: 42
12.2 在 Agent 中使用工具
LangGraph 提供了预构建的组件来简化工具的使用,最核心的就是 create_react_agent。
12.2.1 静态工具列表
这是最常见的使用方式。在创建 Agent 时,直接将一个包含所有可用工具的列表传递给它。
from langgraph.prebuilt import create_react_agent
from langchain_core.tools import tool
# 假设我们已经定义了 multiply 工具
@tool
def multiply(a: int, b: int) -> int:
"""Multiply two numbers."""
return a * b
# 创建 Agent 时,将模型和工具列表传入
agent_executor = create_react_agent(
model="anthropic:claude-3-5-sonnet-latest",
tools=[multiply]
)
# 当用户提问时,Agent 会自动决定是否调用工具
response = agent_executor.invoke({"messages": [("user", "what's 42 multiplied by 7?")]})
# response 会包含 Agent 的完整思考和执行过程
print(response)
12.2.2 动态选择工具
在更复杂的场景中,你可能希望在运行时 (runtime) 根据上下文动态地决定 Agent 可以使用哪些工具。例如,根据用户的权限或当前对话的主题,提供不同的工具集。
这可以通过向 create_react_agent 的 model 参数传递一个配置函数来实现。
- 配置函数要求:
- 该函数必须接收
state作为参数。 - 函数逻辑根据
state或其他上下文信息,筛选出当前可用的工具。 - 函数必须返回一个绑定了所选工具的模型实例 (
model.bind_tools(selected_tools))。
- 该函数必须接收
示例:根据上下文动态提供工具
from typing import Literal, List
from langgraph.prebuilt import create_react_agent, AgentState
from langchain.chat_models import init_chat_model
from langchain_core.tools import tool
# 1. 定义两个不同的工具
@tool
def get_weather() -> str:
"""获取当前天气。"""
return "It's nice and sunny."
@tool
def get_compass_direction() -> str:
"""获取用户当前朝向。"""
return "North"
# 2. 定义一个包含可用工具列表的 State
class DynamicToolState(AgentState):
available_tools: List[Literal["get_weather", "get_compass_direction"]]
# 3. 定义模型配置函数
# 这个函数会在每次 Agent 需要调用 LLM 时执行
def tool_selecting_model(state: DynamicToolState):
"""根据 state 中的 available_tools 动态地为模型绑定工具。"""
# 获取当前状态下允许使用的工具名称列表
allowed_tool_names = state.get("available_tools", [])
# 从所有工具中筛选出被允许的工具
all_tools = [get_weather, get_compass_direction]
selected_tools = [t for t in all_tools if t.name in allowed_tool_names]
print(f"--- Dynamically selecting tools: {[t.name for t in selected_tools]} ---")
# 初始化模型并绑定筛选后的工具
model = init_chat_model("anthropic:claude-3-haiku-20240307")
return model.bind_tools(selected_tools)
# 4. 创建 Agent 时,将配置函数作为 model 参数传入
agent_executor = create_react_agent(
model=tool_selecting_model,
state_schema=DynamicToolState, # 使用自定义的 State
# 注意:这里的 tools 参数可以传入所有可能的工具,用于 ToolNode 执行
tools=[get_weather, get_compass_direction]
)
# 5. 调用 Agent,并在输入中指定本次可用的工具
# 场景一:只允许使用天气工具
input1 = {
"messages": [("user", "how is the weather?")],
"available_tools": ["get_weather"]
}
agent_executor.invoke(input1)
# --- Dynamically selecting tools: ['get_weather'] ---
# Agent 会成功调用 get_weather 工具
# 场景二:不允许使用天气工具
input2 = {
"messages": [("user", "how is the weather?")],
"available_tools": ["get_compass_direction"]
}
agent_executor.invoke(input2)
# --- Dynamically selecting tools: ['get_compass_direction'] ---
# Agent 会因为找不到合适的工具而直接回复,或告知用户无法回答
12.3 预构建工具
除了自定义工具,LangChain 还提供了大量与常见外部系统集成的预构建工具,涵盖了广泛的类别:
- 搜索: Bing, SerpAPI, Tavily
- 代码执行: Python REPL, Node.js REPL
- 数据库: SQL, MongoDB, Redis
- Web 数据: 网页抓取和浏览
- 各类 API: OpenWeatherMap, NewsAPI 等
你可以在 LangChain 集成目录 中浏览所有可用的工具。
13 LangGraph 核心功能:Human-in-the-loop (人工干预)
在构建 Agent 或复杂工作流时,我们经常需要在关键步骤暂停执行,以便人类用户可以审查、编辑、批准或提供额外信息。LangGraph 通过其 “Human-in-the-loop” (HITL) 功能,允许在工作流的任何节点引入人工干预。这对于需要验证模型输出、修正错误或批准高风险操作(如调用付费 API、执行数据库修改)的 LLM 应用至关重要。
13.1 一、核心概念与能力
HITL 的实现依赖于 LangGraph 的两大核心能力:
持久化执行状态 (Persistent Execution State)
- 机制: 中断功能利用 LangGraph 的持久化层 (Persistence Layer)。当图 (Graph) 被中断时,其当前的状态会被完整地保存(创建检查点/Checkpoint)。
- 优势: 这使得图的执行可以被无限期暂停,直到收到人类的指令后再从断点处无缝恢复。这为异步的人工审核或输入提供了支持,不受时间限制。
灵活的集成点 (Flexible Integration Points)
- 人工干预逻辑可以被设计在工作流的任何位置,无论是单个节点内部,还是在节点之间,提供了极高的灵活性。
13.2 二、中断的两种方式
LangGraph 提供了两种中断图执行的方法:
动态中断 (Dynamic Interrupts): 使用
interrupt函数- 描述: 在节点的代码逻辑中,根据图的当前状态动态触发中断。这是最常用和推荐的方式。
- 适用场景: 当需要基于特定条件(例如,LLM 生成了工具调用请求、某个计算结果需要审核)暂停时。
静态中断 (Static Interrupts): 使用
interrupt_before和interrupt_after- 描述: 在编译图时,预先定义好在哪些节点执行之前或之后需要中断。
- 适用场景: 主要用于调试,可以在不修改任何节点代码的情况下,检查特定节点前后的状态。
13.3 三、实现人工干预的核心流程 (使用 interrupt)
从 v1.0 开始,interrupt 是官方推荐的中断方式 (NodeInterrupt 已被弃用)。实现动态中断并恢复的完整流程如下:
步骤 1: 配置 Checkpointer
为了让中断后能够保存状态,必须在编译图时配置一个 checkpointer。InMemorySaver 是一个用于快速开始的内存检查点工具。
步骤 2: 在节点中调用 interrupt()
在需要暂停以等待人类输入的节点中,调用 interrupt() 函数。该函数会暂停图的执行,并可以向人类用户传递当前需要审查的数据。
步骤 3: 使用 thread_id 运行图
调用图的 invoke 或 stream 方法时,必须在 config 中提供一个 thread_id。这个 ID 用于标识和追踪同一个会话的状态。当图中断时,状态会与这个 thread_id 关联保存。
步骤 4: 使用 Command 恢复执行
当图因 interrupt 而暂停后,再次调用 invoke 或 stream 方法,并传入一个 Command 对象来恢复执行。Command 对象可以携带人类用户的输入数据,这些数据会成为 interrupt() 函数的返回值,从而继续后续的流程。
代码示例: 下面是一个完整的流程演示,从中断到恢复。
from typing import TypedDict
from langgraph.graph import StateGraph
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.types import interrupt, Command
# 1. 定义状态
class State(TypedDict):
text_to_process: str
human_review: str
# 2. 定义一个需要人工干预的节点
def request_human_review(state: State):
print("--- 节点:请求人工审核 ---")
print(f"当前文本: {state['text_to_process']}")
# 调用 interrupt() 来暂停图,并传递需要审核的数据
# interrupt() 的返回值将是人类通过 Command 恢复时输入的值
reviewed_text = interrupt(
value={"text_to_revise": state['text_to_process']}
)
print(f"--- 收到人工审核结果:{reviewed_text} ---")
return {"human_review": reviewed_text}
def final_node(state: State):
print("--- 节点:最终处理 ---")
print(f"审核后的最终文本: {state['human_review']}")
return {}
# 3. 构建图
builder = StateGraph(State)
builder.add_node("request_review", request_human_review)
builder.add_node("final", final_node)
builder.set_entry_point("request_review")
builder.add_edge("request_review", "final")
# 4. 编译图,并配置 checkpointer
memory_saver = InMemorySaver()
graph = builder.compile(checkpointer=memory_saver)
# 5. 运行图,它将在 interrupt 处暂停
thread_id = "my-thread-1"
config = {"configurable": {"thread_id": thread_id}}
initial_input = {"text_to_process": "这是一个需要审核的原始文本。"}
# 第一次调用,图会执行到 interrupt 并暂停
result = graph.invoke(initial_input, config=config)
# 打印中断信息,显示图正在等待输入
print("\n--- 图已中断 ---")
print(result['__interrupt__'])
# 6. 模拟人类输入,并使用 Command 恢复图的执行
print("\n--- 人工输入并恢复执行 ---")
human_input = "这是经过人工编辑和确认的文本。"
# 再次调用 invoke,但这次传入一个 Command 对象
final_result = graph.invoke(Command(resume=human_input), config=config)
print("\n--- 图执行完成 ---")
print(f"最终结果: {final_result}")
13.4 四、核心设计模式
利用 interrupt 和 Command,可以实现多种强大的人工干预模式:
批准或拒绝 (Approve or Reject)
- 场景: 在执行关键步骤(如 API 调用、数据库写入)前暂停,让用户确认。
- 实现: 用户输入 “approve” 或 “reject”。图的下一条边可以是一个条件边,根据用户的输入决定是继续执行原计划的节点,还是走向一个处理拒绝逻辑的分支。
编辑图状态 (Edit Graph State)
- 场景: 允许用户审查并修正由 LLM 生成的内容或当前状态中的任何信息。
- 实现: 这是最常见的模式。如上面的代码示例所示,
interrupt()暂停执行,Command(resume=…)传入新的值,该值被用来更新状态。
审查工具调用 (Review Tool Calls)
- 场景: 在 Agent 决定调用某个工具后,但在实际执行工具之前,暂停并让用户审查工具名称和参数。
- 实现: 在负责工具调用的节点中,检查状态中是否有工具调用请求。如果有,则调用
interrupt将工具调用信息呈现给用户。用户可以批准、拒绝或编辑这些调用参数,然后通过Command将修正后的工具调用信息传回,图再继续执行。
验证人类输入 (Validate Human Input)
- 场景: 在一个对话型 Agent 中,当需要用户提供复杂或格式化输入时,可以增加一个验证步骤。
- 实现: 一个节点接收用户输入,另一个节点(或同一个节点中的逻辑)对其进行验证。如果验证失败,可以再次
interrupt并要求用户重新输入。
14 LangGraph 核心概念:多智能体系统 (Multi-agent Systems)
当单个 Agent 的逻辑变得过于复杂,例如工具过多导致决策困难、上下文过于庞大难以追踪,或者需要融合多个专业领域知识时,将应用拆分为多个独立、专一的智能体并进行协作,就构成了一个多智能体系统。这种模式可以显著提升复杂系统的性能和可维护性。
14.1 一、为什么使用多智能体系统?
- 模块化 (Modularity): 将大型系统分解为更小、独立的 Agent,使得开发、测试和维护变得更加容易。
- 专业化 (Specialization): 可以创建专注于特定领域的 " 专家 " Agent(如规划师、研究员、数学专家),从而提升系统的整体表现。
- 可控性 (Control): 你可以明确地定义 Agent 之间的通信方式和协作流程,而不是完全依赖 LLM 的函数调用来决定流程,从而实现更强的控制力。
14.2 二、多智能体架构 (Multi-agent Architectures)
在 LangGraph 中,Agent 通常表现为图中的节点。连接这些 Agent 节点的方式构成了不同的架构:
网络型 (Network):
- 每个 Agent 都可以与其他任何 Agent 直接通信。任何 Agent 都可以决定下一步将控制权交给谁。
主管型 (Supervisor):
- 所有 Agent 都只与一个中心 " 主管 " Agent 通信。由主管负责决策,根据当前任务需求,决定下一步调用哪个专家 Agent。
主管型 - 工具调用模式 (Supervisor - Tool-calling):
- 这是主管型架构的一种特例。每个专家 Agent 被封装成一个 " 工具 “。主管 Agent 通过 LLM 的工具调用能力,来决定调用哪个 “Agent 工具 " 以及传递什么参数。
层级型 (Hierarchical):
- 主管型架构的泛化,可以构建 " 主管的主管 “,形成更复杂的、类似组织架构的层级控制流。
自定义工作流 (Custom Workflow):
- 每个 Agent 只与预定义的一部分 Agent 通信。部分流程是确定性的,只有某些 Agent 节点拥有动态决定下一步走向的能力。
14.3 三、核心交互机制:控制权交接 (Handoffs)
在多智能体系统中,一个 Agent 将控制权和相关信息移交给另一个 Agent 的过程称为交接 (Handoff)。这是实现 Agent 间协作的核心机制。
在 LangGraph 中,Handoff 通过从节点返回一个 Command 对象来实现。Command 对象可以同时包含控制流指令和状态更新。
goto: 指定下一个要跳转到的目标 Agent (节点名)。update: 一个字典,用于更新图的共享状态,从而将信息传递给下一个 Agent。
代码示例:
一个 Agent 节点可以根据内部逻辑,决定下一步是继续自己执行还是将控制权交给 another_agent。
from langgraph.types import Command
from typing import Literal
def agent_node(state) -> Command[Literal["agent_node", "another_agent"]]:
# … 根据内部逻辑(如LLM的输出)决定下一步的走向
next_agent_name = get_next_agent(…)
return Command(
# 1. 指定下一个要调用的 Agent 节点
goto=next_agent_name,
# 2. 更新图的状态,将信息传递过去
update={"messages": ["一条来自 agent_node 的新消息"]}
)
14.4 四、高级 Handoff 模式
子图间的交接 (Handoffs between Subgraphs)
- 在更复杂的结构中,每个 Agent 本身可能就是一个子图 (subgraph)。当一个子图内的某个节点需要将控制权交还给父图中的另一个 Agent 时,可以在
Command中设置graph=Command.PARENT。
# 假设这是 agent_alice 子图中的一个节点 def some_node_inside_alice(state): return Command( goto="agent_bob", # 跳转到父图中的 agent_bob 节点 update={"some_key": "some_value"}, graph=Command.PARENT, # 指明跳转发生在父图中 )- 在更复杂的结构中,每个 Agent 本身可能就是一个子图 (subgraph)。当一个子图内的某个节点需要将控制权交还给父图中的另一个 Agent 时,可以在
将交接包装为工具 (Handoffs as Tools)
- 这是一个非常实用和常见的模式,尤其适用于工具调用型的 Agent。我们可以将 " 切换到另一个 Agent” 这个行为本身封装成一个工具。这样,主管 Agent 就可以通过标准的工具调用方式来决定将任务委派给哪个专家 Agent。
from langchain_core.tools import tool from langgraph.types import Command @tool def transfer_to_research_agent(task: str): """当你需要进行深入研究时,将任务转交给研究专员。""" return Command( goto="research_agent", update={"task_description": task} ) # 主管 Agent 在获得这个工具后,LLM 就可以决策何时调用它, # 从而触发到 research_agent 的控制权交接。
14.5 五、通信与状态管理
Agent 之间需要传递信息才能协作。主要有两种模式:
- 共享状态 (Shared State): 所有 Agent 共享并操作同一个全局状态对象。这是最简单直接的方式,所有信息都对所有 Agent 可见。
- 消息传递 (Message Passing): 每个 Agent 维护自己的内部状态,通过传递消息进行通信。通常,图的状态对象会包含一个消息列表,Agent 通过向这个列表中添加消息来进行交流。
- 混合方法 (Hybrid Approach): 在实践中,通常将两者结合。既有一个共享的状态来存储全局信息(如原始任务),又通过消息列表来处理 Agent 间的对话和协作。这是 LangGraph 中最常见的模式。
15 LangGraph 预构建工具:快速搭建多智能体系统
为了简化多智能体系统的搭建过程,LangGraph 社区提供了一系列预构建的库,用于快速实现两种最流行的多智能体架构:主管模式 (Supervisor) 和 群体模式 (Swarm)。这些工具将底层的图构建、节点定义和路由逻辑封装起来,让开发者可以专注于 Agent 的能力和协作逻辑。
15.1 一、主管模式 (Supervisor)
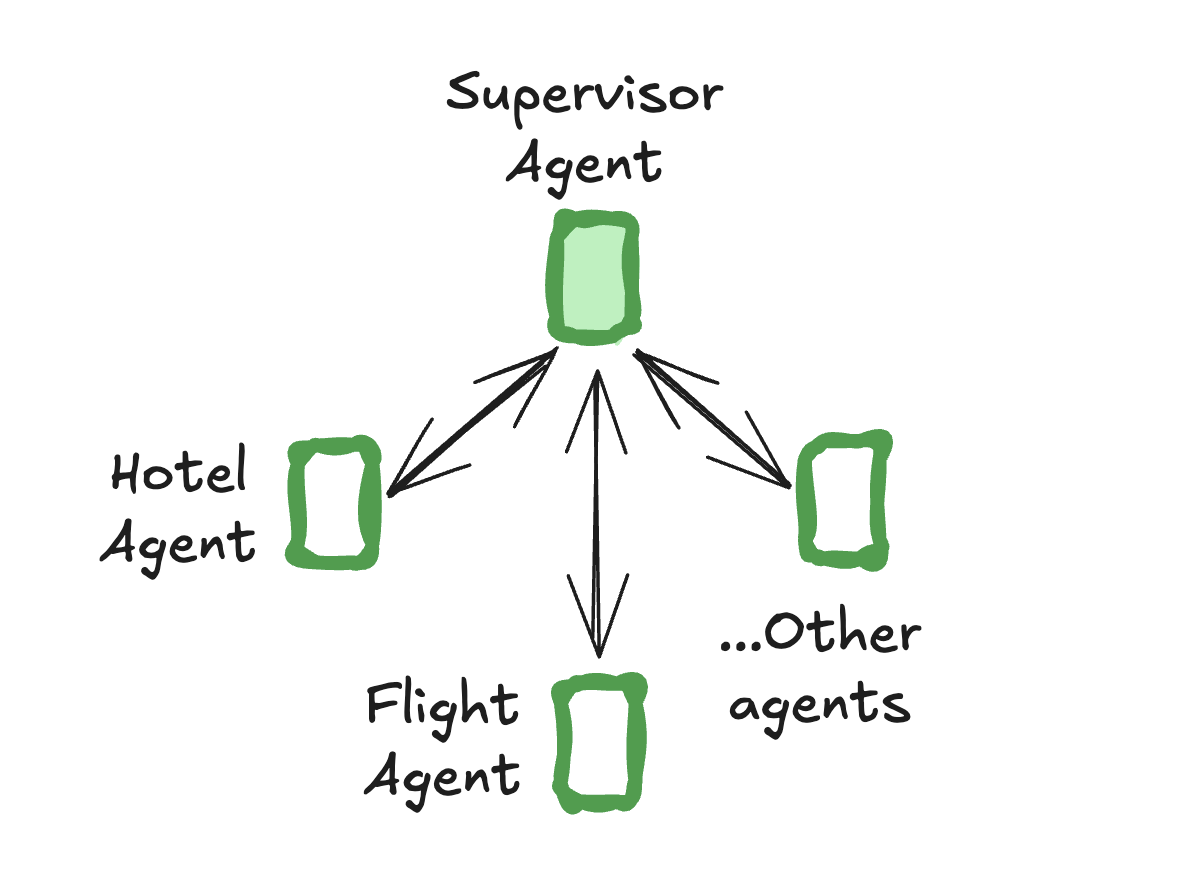
核心思想:一个中心的 " 主管 " (Supervisor) Agent 负责协调一组 " 专家 " (Specialist) Agent。所有任务首先到达主管,由主管根据任务内容决定将其分配给哪个专家 Agent。专家 Agent 完成自己的部分后,将结果返回给主管,再由主管决定下一步行动(例如,将任务交给另一个专家,或结束流程)。这就像一个项目经理将任务分配给不同的团队成员。
实现方式:使用 langgraph-supervisor 库。
核心步骤:
安装库:
pip install langgraph-supervisor创建专家 Agent: 使用 LangGraph 的预构建函数
create_react_agent来定义各个领域的专家。每个专家 Agent 都有自己的:name: 唯一的名称,用于主管进行识别和调用。prompt: 描述其角色和能力的提示词。tools: 该专家能够使用的专属工具列表。
创建主管 Agent: 使用
create_supervisor函数来组装整个系统。你需要提供:agents: 一个包含所有专家 Agent 的列表。model: 供主管 Agent 使用的 LLM。prompt: 指导主管如何管理和分配任务的系统级提示。
代码示例:
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
from langgraph_supervisor import create_supervisor
# 1. 定义专家 Agent 的工具
def book_flight(from_airport: str, to_airport: str):
"""预订机票"""
return f"成功预订从 {from_airport} 到 {to_airport} 的机票。"
def book_hotel(hotel_name: str):
"""预订酒店"""
return f"成功在 {hotel_name} 预订住宿。"
# 2. 创建两个专家 Agent
flight_assistant = create_react_agent(
model="openai:gpt-4o",
tools=[book_flight],
prompt="你是一个机票预订助理",
name="flight_assistant"
)
hotel_assistant = create_react_agent(
model="openai:gpt-4o",
tools=[book_hotel],
prompt="你是一个酒店预订助理",
name="hotel_assistant"
)
# 3. 创建主管 Agent,并传入专家 Agent 列表
supervisor_graph = create_supervisor(
agents=[flight_assistant, hotel_assistant],
model=ChatOpenAI(model="gpt-4o"),
prompt="你管理一个酒店预订助理和一个机票预订助理。请将工作分配给他们。"
).compile()
# 4. 运行主管图
# 主管会先分析用户输入,然后决定先调用 flight_assistant,
# 完成后再调用 hotel_assistant。
response = supervisor_graph.invoke({
"messages": [{
"role": "user",
"content": "请帮我预订一张从BOS到JFK的机票,并预订McKittrick酒店。"
}]
})
15.2 二、群体模式 (Swarm)
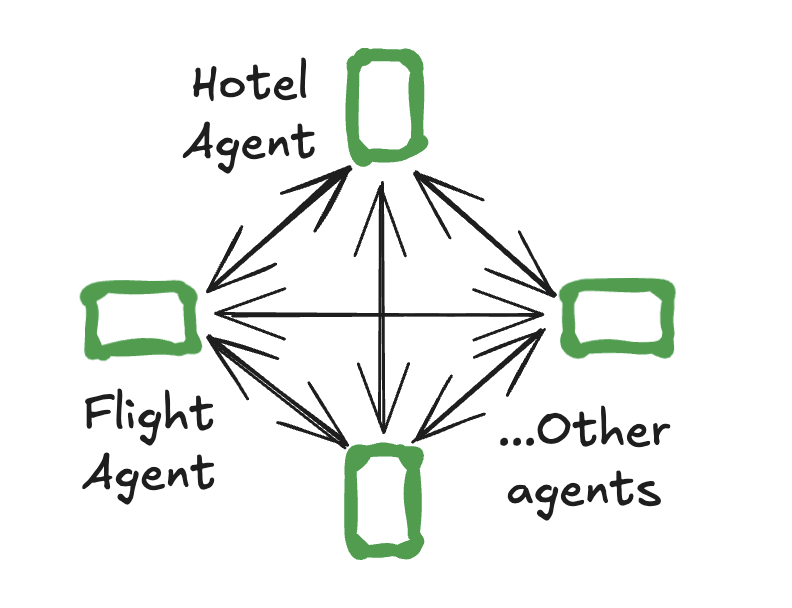
核心思想:与主管模式的中心化控制不同,群体模式允许 Agent 之间根据各自的专长动态地、点对点地移交控制权。这种架构更加灵活,Agent 之间可以直接通信和协作,而无需通过中心节点。系统会记住最后一个活跃的 Agent,以便在后续交互中从该 Agent 处继续对话。
实现方式:使用 langgraph-swarm 库。
核心步骤:
安装库:
pip install langgraph-swarm创建与配置: 其创建方式与 Supervisor 类似,通常也会涉及定义一组专家 Agent。但其内部的路由逻辑不同,它允许 Agent 之间直接调用,而不是必须经过中心主管。每个 Agent 的工具中通常会包含用于 " 切换 " 到其他 Agent 的特殊工具。
15.3 三、如何选择:Supervisor Vs. Swarm
- 选择 Supervisor 模式:
- 当你的工作流有明确的中心化控制需求时。
- 当任务可以被清晰地分解并分配给不同的专家时。
- 当需要一个 " 总负责人 " 来协调和汇总结果时。
- 流程更清晰,易于管理和调试。
- 选择 Swarm 模式:
- 当需要更动态、灵活的协作时。
- 当 Agent 之间的交互路径不固定,需要根据对话内容自由跳转时。
- 适用于模拟更复杂的、非层级的协作关系,例如一个团队中的成员自由讨论。
16 LangGraph 指南:构建自定义多智能体系统
当预构建的 Supervisor 或 Swarm 架构无法满足复杂的业务需求时,我们可以利用 LangGraph 的底层能力,从零开始构建自定义的多智能体系统。其核心在于精确控制 Agent 之间的通信与控制权流转。
16.1 一、核心机制:Handoffs (控制权交接)
Handoff 是实现多智能体协作的基础模式,它描述了一个 Agent 如何将控制权移交给另一个 Agent。一个完整的 Handoff 包含两个关键部分:
- 目的地 (Destination): 要将控制权移交给的目标 Agent 的名称(即图中的节点名)。
- 载荷 (Payload): 需要传递给目标 Agent 的信息,通常是通过更新图的共享状态 (State) 来实现。
16.2 二、实现 Handoff 的最佳实践:将交接封装为工具
在 LangGraph 中,最强大和灵活的 Handoff 实现方式是将 " 切换 Agent” 这个行为本身封装成一个工具。这样,一个 Agent(如主管)就可以通过标准的工具调用(Tool Calling)来决定何时以及将任务委派给哪个专家 Agent。
1. 创建 Handoff 工具
我们可以创建一个工厂函数,用于动态生成 " 转移到指定 Agent” 的工具。
from typing import Annotated
from langchain_core.tools import tool, InjectedToolCallId
from langgraph.graph import MessagesState
from langgraph.prebuilt import InjectedState
from langgraph.types import Command
def create_handoff_tool(*, agent_name: str, description: str):
"""一个工厂函数,用于创建“转移到特定Agent”的工具。"""
@tool(f"transfer_to_{agent_name}", description=description)
def handoff_tool(
# Annotated 和 InjectedState 是关键,它允许工具在执行时自动获取当前的图状态。
state: Annotated[MessagesState, InjectedState],
# 获取此次工具调用的唯一ID。
tool_call_id: Annotated[str, InjectedToolCallId],
) -> Command:
"""
这个工具的返回值不是一个普通值,而是一个 Command 指令对象,
用于指导 LangGraph 的流程。
"""
tool_message = {
"role": "tool",
"content": f"成功将控制权转移给 {agent_name}",
"name": f"transfer_to_{agent_name}",
"tool_call_id": tool_call_id,
}
return Command(
# 1. 目的地:跳转到名为 agent_name 的图节点。
goto=agent_name,
# 2. 载荷:更新全局状态,将本次切换操作的消息加入消息列表。
update={"messages": state["messages"] + [tool_message]},
# 3. 指定图层:当Agent是子图时,必须使用 PARENT
# 来表示跳转到父图中的另一个节点。
graph=Command.PARENT,
)
return handoff_tool
2. Handoff 工具的工作流程
- 主管 Agent 决策:主管 Agent 的 LLM 根据当前任务和对话历史,判断需要调用某个专家。它会生成一个对
transfer_to_…工具的调用。 - 工具节点执行:LangGraph 的工具节点执行这个
handoff_tool。 - 返回
Command对象:该工具不返回计算结果,而是返回一个Command指令。 - LangGraph 路由:LangGraph 解释
Command对象,暂停当前 Agent 的执行,更新全局状态,并将控制权(和更新后的状态)传递给goto指定的下一个 Agent 节点。
16.3 三、处理返回 Command 的工具
当你的工具返回 Command 对象时,你需要确保执行该工具的节点能够正确处理它。
- 使用预构建组件:LangGraph 的预构建
create_react_agent或ToolNode已经内置了对Command返回值的处理逻辑,可以直接使用。 - 自定义工具节点:如果你自定义工具执行节点,你需要确保该节点能够收集所有工具返回的
Command对象,并将它们作为节点自身的返回值,以便 LangGraph 引擎进行后续的路由处理。
16.3.1 四、重要假设
这种将 Handoff 封装为工具的实现模式,通常基于一个重要的设计假设:
- 共享的全局状态:系统中的所有 Agent 共享同一个全局状态(例如,一个包含所有消息的
MessagesState)。每个 Agent 都能看到完整的对话历史,从而做出正确的决策。如果需要更精细的控制(例如,每个 Agent 只能看到部分信息),则需要设计更复杂的状态管理和数据传递逻辑。
17 LangGraph 指南:通过 MCP 集成外部工具
为了更好地实现工具的模块化和解耦,LangGraph 支持与 模型上下文协议 (Model Context Protocol, MCP) 集成。MCP 是一个开放协议,旨在标准化应用程序向语言模型提供工具和上下文的方式。通过 langchain-mcp-adapters 库,我们可以让 LangGraph Agent 无缝地使用部署在外部 MCP 服务器上的工具。
这种架构的优势在于,工具的实现和维护可以与 Agent 的逻辑完全分离。工具可以作为独立的服务运行,甚至可以由不同的团队用不同的语言开发。
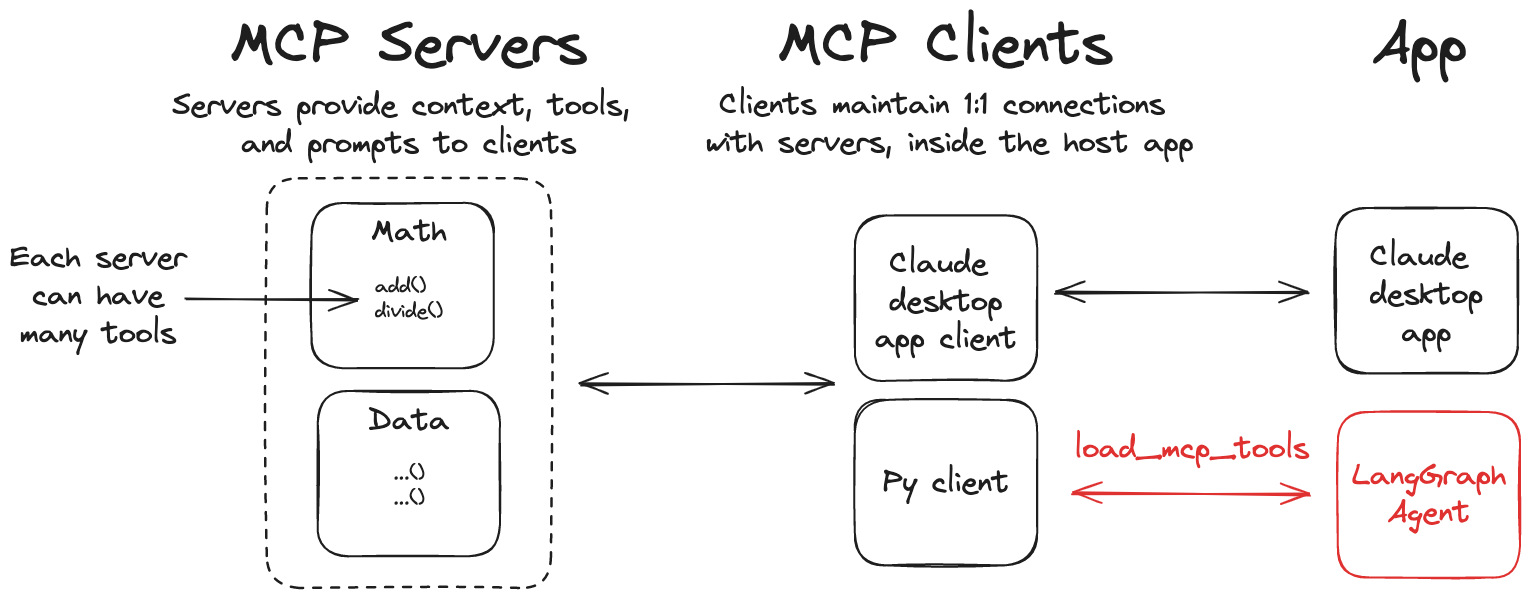
17.1 一、核心步骤与组件
1. 安装适配器库
pip install langchain-mcp-adapters
2. 配置 MCP 客户端
核心组件是 MultiServerMCPClient。这个客户端负责连接到一个或多个 MCP 工具服务器,并从中获取工具定义。
在初始化客户端时,你需要提供一个字典,其中每个键是服务器的唯一名称,值是该服务器的连接配置。
- 本地脚本 (stdio): 通过标准输入/输出与本地运行的脚本进行通信。
command: 运行脚本的命令 (如python)。args: 脚本的路径和参数。transport: 固定为"stdio"。
- Web 服务 (streamable_http): 通过 HTTP 与远程服务器通信。
url: MCP 服务器的端点 URL。transport: 固定为"streamable_http"。
代码示例:配置客户端
from langchain_mcp_adapters.client import MultiServerMCPClient
client = MultiServerMCPClient({
# 服务器1: 本地数学工具,通过 stdio 运行
"math": {
"command": "python",
# 注意:这里需要替换为你本地 math_server.py 脚本的绝对路径
"args": ["/path/to/your/math_server.py"],
"transport": "stdio",
},
# 服务器2: 远程天气工具,通过 HTTP 访问
"weather": {
# 确保天气服务在 http://localhost:8000/mcp 上运行
"url": "http://localhost:8000/mcp",
"transport": "streamable_http",
}
})
3. 获取并使用工具
配置好客户端后,可以异步调用 client.get_tools() 方法。该方法会连接所有已配置的服务器,获取它们的工具定义,并将其转换为 LangChain 标准的工具列表。
# 异步获取所有 MCP 服务器上定义的工具
tools = await client.get_tools()
得到的 tools 列表可以像任何普通的 LangChain 工具一样在 LangGraph 中使用。
17.2 二、集成方式
有两种主要方式可以将 MCP 工具集成到 LangGraph 工作流中:
方式一:使用预构建的 create_react_agent
这是最简单直接的方法。只需将从 MCP 客户端获取的 tools 列表直接传递给 create_react_agent 函数即可。Agent 会自动将这些外部工具纳入其可用的工具集中。
代码示例:
from langgraph.prebuilt import create_react_agent
# 1. (前续步骤) 配置 client 并获取 tools
# client = MultiServerMCPClient(...)
# tools = await client.get_tools()
# 2. 创建 Agent,直接传入 MCP 工具
agent_executor = create_react_agent(
model="anthropic:claude-3-5-sonnet-latest",
tools=tools
)
# 3. 调用 Agent
# Agent 会根据问题,自动调用部署在 MCP 服务器上的工具
response = await agent_executor.ainvoke(
{"messages": [{"role": "user", "content": "what's (3 + 5) x 12?"}]}
)
方式二:在自定义图中使用 ToolNode
对于更复杂的自定义图,你可以将 MCP 工具集成到一个 ToolNode 中。这个节点专门负责执行工具调用。
代码示例:
from langgraph.graph import StateGraph, MessagesState, START, END
from langgraph.prebuilt import ToolNode
# 1. (前续步骤) 配置 client 并获取 tools
# client = MultiServerMCPClient(...)
# tools = await client.get_tools()
# 2. 定义图的状态和节点
graph_builder = StateGraph(MessagesState)
# 定义 Agent 节点 (负责思考和决定调用哪个工具)
def agent_node(state):
# ... (调用 LLM,生成工具调用请求)
return {"messages": [response_message]}
# 使用 MCP 工具列表创建 ToolNode
tool_node = ToolNode(tools)
# 3. 构建图
graph_builder.add_node("agent", agent_node)
graph_builder.add_node("tools", tool_node)
graph_builder.add_edge(START, "agent")
# ... (添加从 agent 到 tools 以及从 tools 回到 agent 的条件边)
graph = graph_builder.compile()
通过这种方式,你可以将外部、解耦的工具无缝集成到任何结构的 LangGraph 工作流中,极大地增强了系统的灵活性和可扩展性。
18 LangGraph 指南:使用子图 (Subgraphs) 构建模块化系统
子图(Subgraph)是 LangGraph 中实现 封装 (encapsulation) 和 模块化 的核心概念。简单来说,一个子图其本身是一个完整的、可独立运行的图(Graph),但它又可以被当作一个节点(Node)嵌入到另一个更上层的父图(Parent Graph)中。
这种设计模式允许我们构建高度复杂且层次分明的系统。
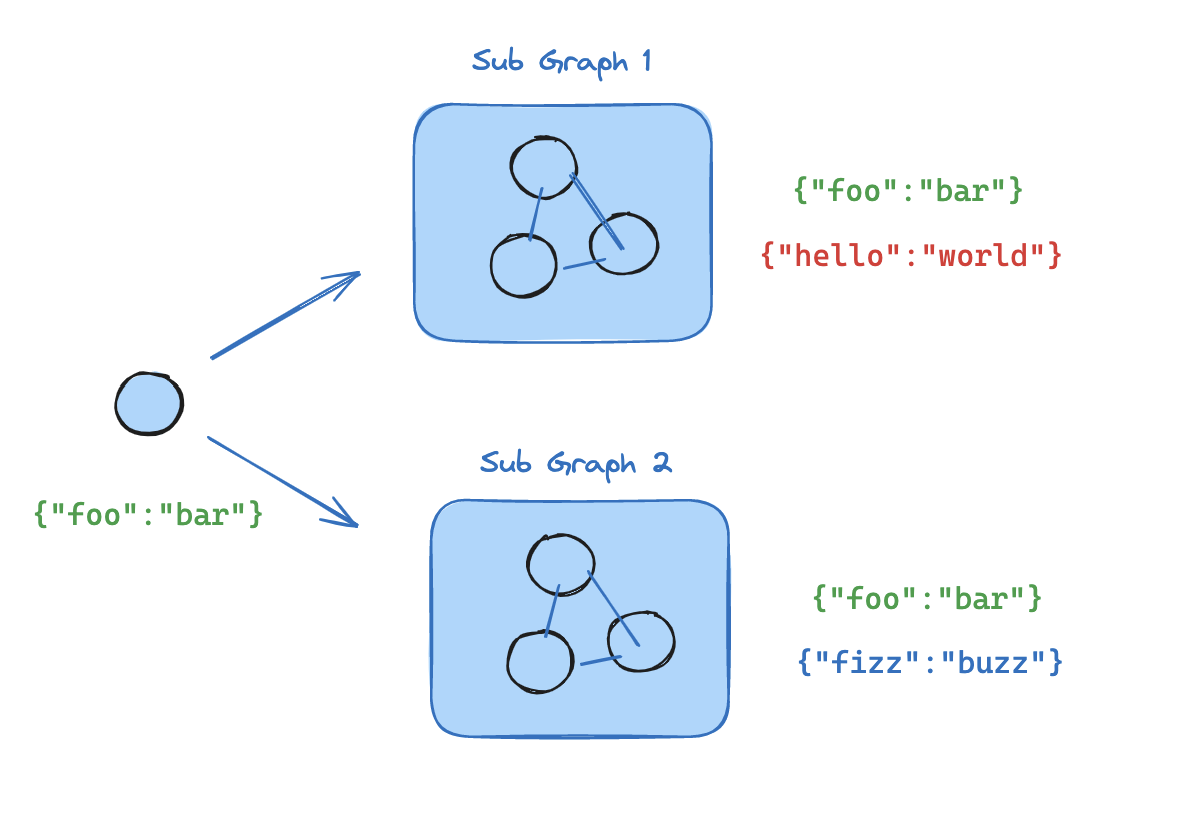
18.1 一、为何使用子图?
使用子图主要有三个优势:
- 构建多智能体系统 (Multi-agent Systems):每个智能体可以被封装成一个独立的子图,父图则负责协调这些智能体之间的交互流程。
- 逻辑复用 (Reusability):如果一组节点逻辑需要在多个不同的图中重复使用,可以将其封装成一个子图,在需要的地方直接调用,无需重复编写。
- 独立开发与解耦 (Decoupling):不同团队可以并行开发图的不同部分。只要预先定义好子图的输入和输出接口(即 State Schema),各团队就可以独立工作,最后将所有子图组装成一个完整的系统,而无需关心彼此内部的实现细节。
18.2 二、核心挑战:状态通信
使用子图时最核心的问题是:父图与子图之间如何通信? 具体来说,就是它们如何传递和同步状态(State)。根据父图和子图状态结构(State Schema)的异同,存在两种主要的集成模式。
18.3 三、集成模式一:共享状态 (Shared State Schema)
当父图和子图的状态结构兼容或完全相同时(即它们拥有共享的状态键),可以采用这种最直接、最简洁的集成方式。
实现方式:
将编译好的子图实例直接作为父图的一个节点,通过 builder.add_node() 添加。LangGraph 会自动处理状态的传递,将父图的当前状态无缝地传递给子图。
关键代码:
from langgraph.graph import StateGraph, MessagesState, START
# 假设父图和子图都使用通用的 MessagesState
# class MessagesState(TypedDict):
# messages: Annotated[list[AnyMessage], add_messages]
# 1. 定义并编译子图
# sub_builder = StateGraph(MessagesState)
# … 添加子图的节点和边 …
subgraph = sub_builder.compile()
# 2. 定义父图,并将子图作为节点添加
parent_builder = StateGraph(MessagesState)
parent_builder.add_node("subgraph_node", subgraph) # <-- 核心步骤
# 3. 构建父图的流程
parent_builder.add_edge(START, "subgraph_node")
# … 可以继续添加其他节点和边 …
graph = parent_builder.compile()
# 调用时,父图的状态会直接被子图使用
graph.invoke({"messages": [{"role": "user", "content": "hi!"}]})
这种模式下,子图就像一个黑盒函数,接收父图的状态,处理后返回更新后的状态,整个过程非常流畅。
18.4 四、集成模式二:独立状态 (Different State Schemas)
当父图和子图的状态结构不兼容时,例如它们由不同团队开发,或子图需要一个非常特定的状态格式,就需要一个 " 适配器 " 层。
实现方式:
在父图中创建一个常规的函数节点。在这个节点的函数内部,手动调用子图的 .invoke() 方法。这个节点的核心职责是:
- 接收父图的状态。
- 将父图的状态数据转换成子图能够理解的输入格式。
- 调用
subgraph.invoke()并等待其完成。 - 将子图的返回结果转换回父图能够理解的格式,并更新父图的状态。
关键代码:
from typing_extensions import TypedDict, Annotated
from langchain_core.messages import AnyMessage
from langgraph.graph import StateGraph, MessagesState
from langgraph.graph.message import add_messages
# 1. 定义子图独有的状态
class SubgraphState(TypedDict):
subgraph_messages: Annotated[list[AnyMessage], add_messages]
# … 定义并编译使用 SubgraphState 的子图 …
subgraph = subgraph_builder.compile()
# 2. 在父图中,定义一个“适配器”节点函数
def call_subgraph_node(state: MessagesState) -> dict:
# 从父图状态 (MessagesState) 映射到子图输入
subgraph_input = {"subgraph_messages": state["messages"]}
# 调用子图
subgraph_output = subgraph.invoke(subgraph_input)
# 将子图输出 (SubgraphState) 映射回父图状态更新
return {"messages": subgraph_output["subgraph_messages"]}
# 3. 将这个适配器函数添加为父图的节点
parent_builder = StateGraph(MessagesState)
parent_builder.add_node("adapter_for_subgraph", call_subgraph_node) # <-- 核心步骤
# … 构建父图流程 …
graph = parent_builder.compile()
这种模式虽然需要编写额外的适配代码,但提供了极高的灵活性和解耦度,确保了即使子图的内部实现或状态结构发生变化,只要适配器逻辑更新得当,父图的其余部分就不受影响。
总结: 子图是 LangGraph 中构建大型、可维护系统的关键。选择哪种集成方式取决于你的状态管理策略:状态共享时,直接添加为节点;状态独立时,通过适配器节点调用。